
- The New York City’s Metropolitan Transit Authority (MTA) has implemented facial recognition systems in the subway to identify people who are not paying their fares.
- Eurostar launched the world’s first walk-through biometric corridor to access its trains.
- G/O Media, publisher of The Onion and Gizmodo, among the others, has begun publishing AI-generated articles.
- In the What Can AI Do for Me? section, we see how to use GPT-4 Code Interpreter to ask questions about our website performance that Google Analytics can’t answer without attending a 72 days class.
- In the Prompting section, I recommend what use case is more suitable for seven AI systems that can be used today.
Synthetic Work takes a week off. This newsletter is written by a real human, not an AI, and that human needs a little break.
Expect the next issue on August 6th.
With that in mind, let’s talk about business.
Alessandro
What we talk about here is not about what it could be, but about what is happening today.
Every organization adopting AI that is mentioned in this section is recorded in the AI Adoption Tracker.
In the Transportation industry, New York City’s Metropolitan Transit Authority (MTA) has implemented facial recognition systems in the subway to identify people who are not paying their fares.
Kevin Collier, reporting for NBC News:
The system was in use in seven subway stations in May, according to a report on fare evasion published online by the Metropolitan Transit Authority, which oversees New York City’s public transportation. The MTA expects that by the end of the year, the system will expand by “approximately two dozen more stations, with more to follow,” the report says. The report also found that the MTA lost $690 million to fare evasion in 2022.
Joana Flores, an MTA spokesperson, said the AI system doesn’t flag fare evaders to New York police, but she declined to comment on whether that policy could change.
…
“We’re using it essentially as a counting tool,” Minton said. “The objective is to determine how many people are evading the fare and how are they doing it.”Minton said the videos are stored on the MTA’s servers and are kept “for a limited period.” New York Gov. Kathy Hochul’s office announced last year that the city’s transit systems had more than 10,000 surveillance cameras.
Use of the software adds to what some privacy advocates see as a growing surveillance apparatus developing in New York City.
…
The software was created by the Spanish company AWAAIT, Flores confirmed.
…
A heavily redacted MTA contract for the AI system from July 2022, which Cahn acquired through a Freedom of Information Law request and shared with NBC News, shows that the system was first tested in New York City in 2020, with more stations added in 2021. The exact number of stations is redacted. GovSpend, a database of government spending records, shows that the MTA made two purchases in 2021 for “AWAAIT Video Analytics Fare Evasion Software,” for a combined $35,335. Figures for 2022 weren’t available.
The original MTA report is here.
In general, no matter how slowly, we should assume that the world will move to facial and palm recognition not just to curb law violations, but also to remove friction from mundane activities that we perform dozens of times a day, like payments or access to buildings and facilities.
In fact, it’s the latter use case that will justify the former, giving people a reason to trade the loss of privacy for convenience.
Eventually, we’ll look back and think that it’s ridiculous we had to take out our wallets first and then our phones to pay for things.
More of the same: In the Transportation industry, Eurostar launched the world’s first walk-through biometric corridor to access its trains.
Thomas Macaulay, reporting for The Next Web:
The first-ever biometric corridor for train travel opened today at Eurostar’s London terminal.
The system, developed by British tech firm iProov, replaces border checks with a facial verification checkpoint that you just walk straight past.
Before travel, the passenger downloads the app, authenticates their ID, scans their face, and links their ticket. On arrival at St Pancras Station, they stroll through a dedicated lane for the tech — dubbed SmartCheck — which verifies their entry.
The system lets users skip ticket gates and manual border control in the UK. After baggage inspection and a passport check at the French border, they’re free to board the train.
…
Initially, the system will only be available for Eurostar’s Business Premier and Carte Blanche passengers. But the company aims to extend the service to all customers and — perhaps — more borders.
…
SmartCheck is years in the making. In 2020, the UK’s Department for Transport awarded iProov part of a £9.4m fund for innovative rail projects, which was used to develop the biometric system. The next year, live trials of the contactless service began at Eurostar.
…
At peak levels, around 11 million annual Eurostar customers pass through an area the size of three tennis courts — which means efficient checks are vital.
…
According to Bud, the biometric systems in airports are more intrusive than SmartCheck.“The information all flows through the airport backbone, so your face and identity data is controlled by the airlines and the facial verification system in the airport,” Bud said. “In this case, it’s sitting in your phone.”
Bud is keen to address concerns about surveillance. According to iProov, all personal data is stored securely on the user’s smartphone and encrypted during operation. Once verified, the information is only shared with the ticket gate and passport control services. After a maximum of 48 hours, it’s deleted from these systems.
…
SmartCheck is strictly an opt-in product. The users, he adds, will only be compared to images they submit, rather than any mass database.“This is not surveillance,” he said. “A user can choose to enrol and use SmartCheck or not — and nobody will ever compel them to do so.”
…
Another concern around biometrics involves AI biases. Studies have shown that facial recognition has higher error rates for certain skin tones, genders, and ages. According to iProov, these biases have now been addressed in industry-leading systems.
As I said, we’ll trade privacy for convenience. And no, biases in facial recognition have not been addressed.

In the Publishing industry, G/O Media, publisher of The Onion and Gizmodo, among the others, has begun publishing AI-generated articles, and the employees are not happy about it.
Pranshu Verma, reporting for The Washington Post:
A few hours after James Whitbrook clocked into work at Gizmodo on Wednesday, he received a note from his editor in chief: Within 12 hours, the company would roll out articles written by artificial intelligence. Roughly 10 minutes later, a story by “Gizmodo Bot” posted on the site about the chronological order of Star Wars movies and television shows.
…
Whitbrook — a deputy editor at Gizmodo who writes and edits articles about science fiction — quickly read the story, which he said he had not asked for or seen before it was published. He catalogued 18 “concerns, corrections and comments” about the story in an email to Gizmodo’s editor in chief, Dan Ackerman
…
The article quickly prompted an outcry among staffers who complained in the company’s internal Slack messaging system that the error-riddled story was “actively hurting our reputations and credibility,” showed “zero respect” for journalists and should be deleted immediately, according to messages obtained by The Washington Post. The story was written using a combination of Google Bard and ChatGPT, according to a G/O Media staff member familiar with the matter.
…
“I have never had to deal with this basic level of incompetence with any of the colleagues that I have ever worked with,” Whitbrook said in an interview. “If these AI [chatbots] can’t even do something as basic as put a Star Wars movie in order one after the other, I don’t think you can trust it to [report] any kind of accurate information.”
As we said many times in Synthetic Work, as people start to realize that generative AI is a threat to their jobs, they will start to get hostile, questioning the reputation of the tech, possibly to the point of sabotaging it to prove it’s unreliable.
We’ll see a lot more of this going forward.
Let’s continue:
On June 29, Merrill Brown, the editorial director of G/O Media, had cited the organization’s editorial mission as a reason to embrace AI. Because G/O Media owns several sites that cover technology, he wrote, it has a responsibility to “do all we can to develop AI initiatives relatively early in the evolution of the technology.”
“These features aren’t replacing work currently being done by writers and editors,” Brown said in announcing to staffers that the company would roll out a trial to test “our editorial and technological thinking about use of AI.” “There will be errors, and they’ll be corrected as swiftly as possible,” he promised.
…
Mark Neschis, a G/O Media spokesman, said the company would be “derelict” if it did not experiment with AI. “We think the AI trial has been successful,” he said in a statement. “In no way do we plan to reduce editorial headcount because of AI activities.” He added: “We are not trying to hide behind anything, we just want to get this right. To do this, we have to accept trial and error.”
The narrative is that news publishers, especially the ones focused on tech, cannot ignore AI as their job is to embrace what’s new and report about it.
Next time you hear that narrative, ask what’s their journey in building their very own quantum computer. You might receive a different answer. If you do, at least ask if they are investigating the purchase of a fusion reactor. If they object that these new technologies are not really adjacent to their core business, ask them about launching a network of satellites via SpaceX’s reusable rockets.
That should do.
Let’s finish the article:
Gizmodo’s union released a statement on Twitter decrying the stories. “This is unethical and unacceptable,” they wrote. “If you see a byline ending in ‘Bot,’ don’t click it.” Readers who click on the Gizmodo Bot byline itself are told these “stories were produced with the help of an AI engine.”
…
Lauren Leffer, a Gizmodo reporter and member of the Writers Guild of America, East union, said this is a “very transparent” effort by G/O Media to get more ad revenue because AI can quickly create articles that generate search and click traffic and cost far less to produce than those by a human reporter.She added the trial has demoralized reporters and editors who feel their concerns about the company’s AI strategy have gone unheard and are not valued by management. It isn’t that journalists don’t make mistakes on stories, she added, but a reporter has incentive to limit errors because they are held accountable for what they write — which doesn’t apply to chatbots.
Of course, people will click the articles, bot byline or not. When we are not directly affected by AI, AI is amazing. It’s a novelty, it’s entertaining, it’s starting to do a better job than people in terms of quality, it’s faster, and makes things cheaper.
When we have all these wonderful things to think about, do you really expect us to pause and think “Wait a minute. What about the people who will lose their jobs if I click this?”
Last week, in Issue #21 – Investigating absurd hypotheses with GPT-4, we saw how the new GPT-4 Code Interpreter model in ChatGPT can be used to generate and overlap charts to look for correlations.
This week, let’s take another look at the same model to generate an interactive map instead of a static chart.
Notice that I have an ulterior motive to show you the rather simple use case below: I want to make a statement.
I want to highlight how generative AI models are threatening a wide range of established products by radically simplifying the interaction with data.
What you’ll see below is part of the reasons why Google rang all alarms bells once OpenAI started to gain traction with ChatGPT.
Ok. Let’s say that we are trying to understand better the data we collect from one of our websites.
Like millions of other individuals and companies in the world, we are probably using Google Analytics because it’s free and it’s considered the gold standard in analytics reporting.
Google Analytics used to be a decent product 20 years ago. Today, it’s so complicated to use that we have no clue how to find the answers to our questions, let alone surface unexpected insights.
So, let’s say that we want to know something innocuous like what are the top websites driving traffic towards our website for each visiting country.
Let’s try to ask that question to Google Analytics, which implemented a natural language interface a few years ago for this very purpose:
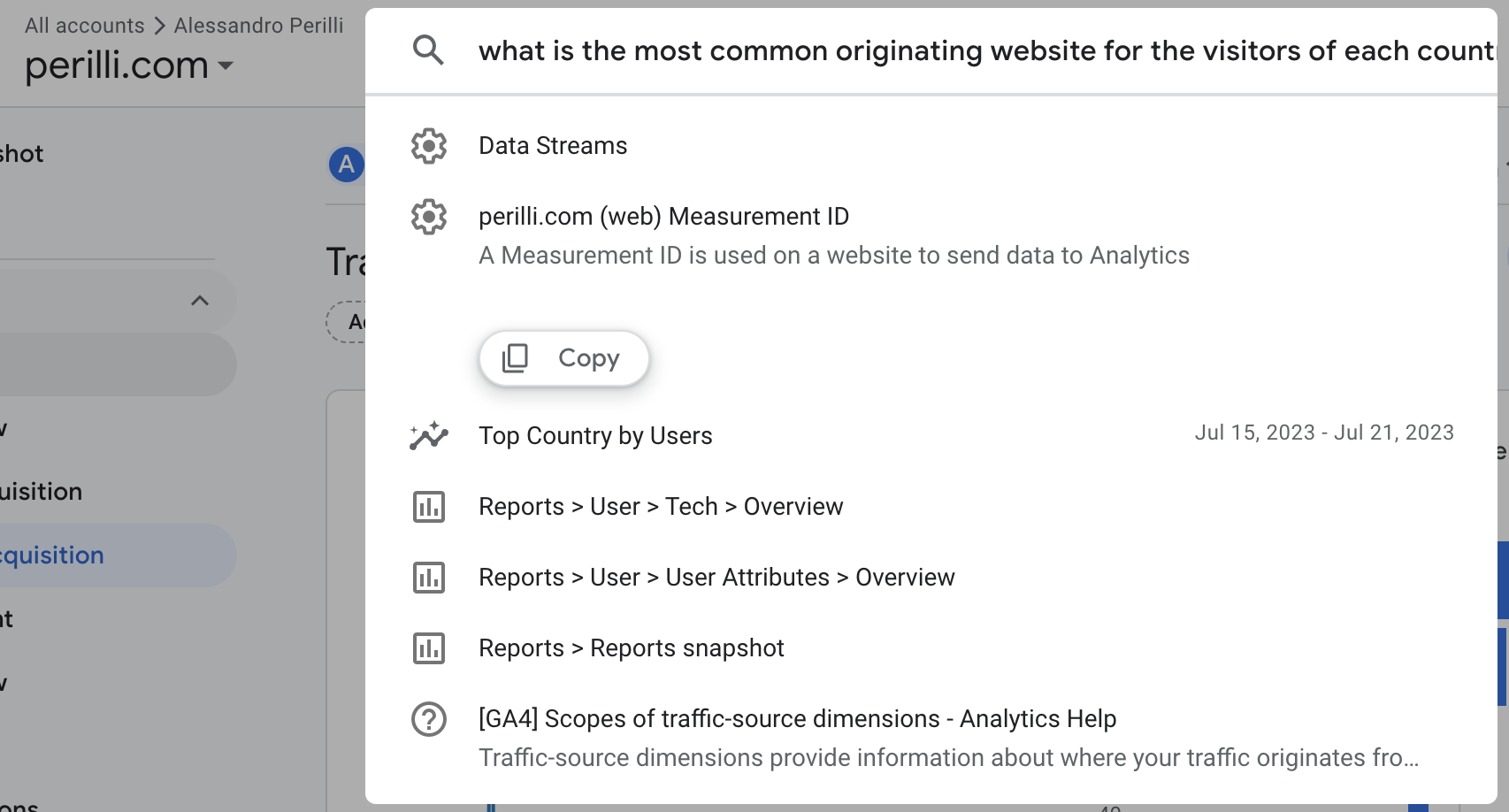
Embarrassing.
But it’s embarrassing only because exceptional generative AI models exist in the world. Just two years ago, my comment to the screenshot above would have been “Terrible. It never worked and it never will.”
I am sure there’s a way to get the simple answer we are looking for from Google Analytics, if you take a week off to do an online class and 30 hours of practice, but nobody wants to commit that sort of time to this task.
So, let’s try to ask the same question to ChatGPT with the GPT-4 Code Interpreter model:
Notice, as usual, the use of two basic techniques we have in the How to Prompt section of Synthetic Work: Assign a Role and Ask For Follow-up Questions.
Earlier this week, OpenAI has announced a new beta capability called Custom Instructions, which allows you to define a per-session system prompt, conditioning every interaction you have with the AI model within that session. In a future Splendid Edition, we’ll see how to use it to avoid bloating our prompts with these basic techniques.
Back to our attempt to overcome the inadequacy of Google Analytics.
GPT-4 Code Interpreter complies with the request and suggests a few areas of exploration, but we want an answer to our original question:

GPT-4 complies again and provide a basic, correct answer to see if it correctly interpreted our request. The formatting of the answer is rather disappointing, but this, too, can be fixed with the new Custom Instructions feature.
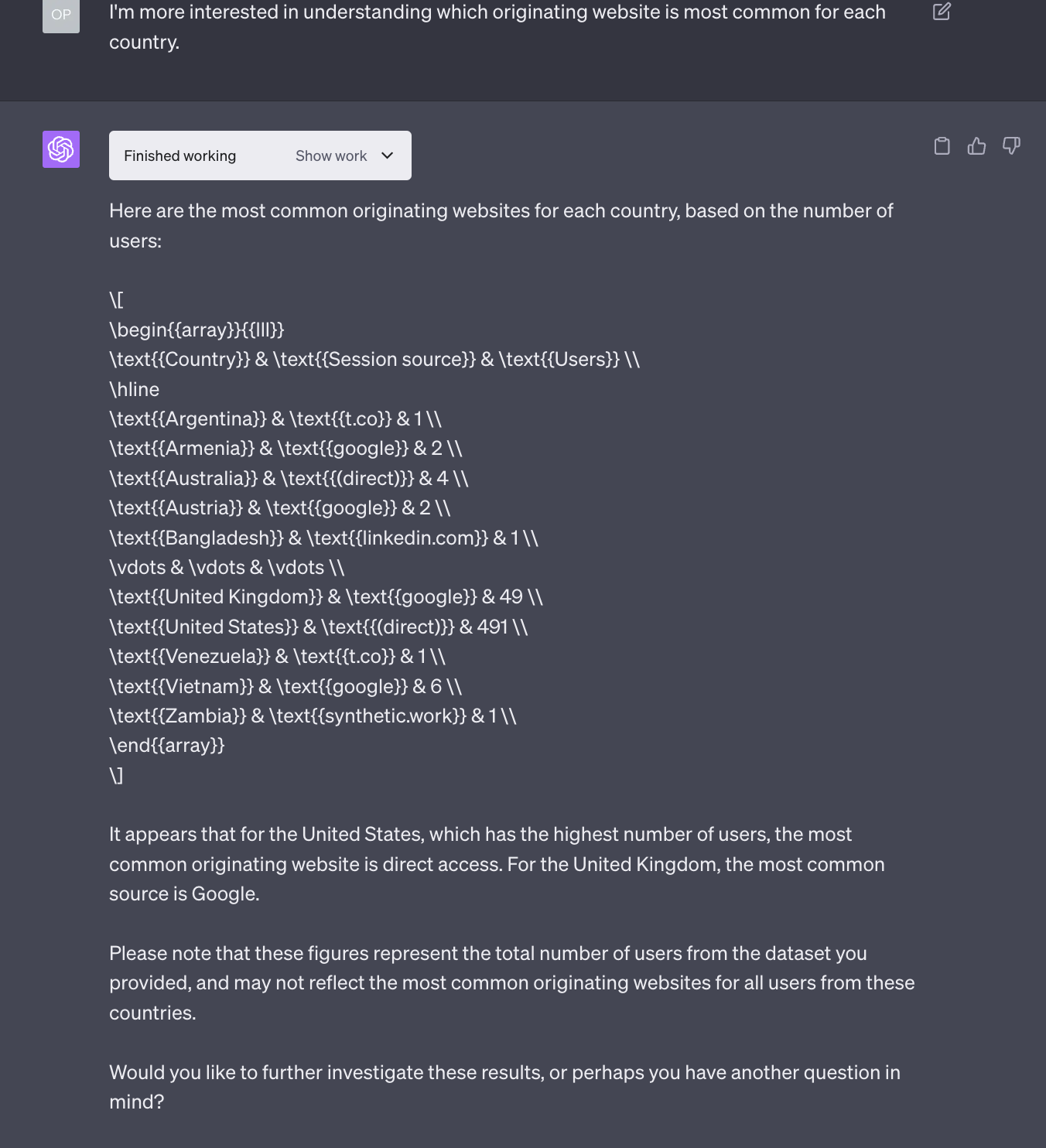
For now, we’ll simply ask to continue in this direction and generate an interactive map to visualize the answer we are looking for:
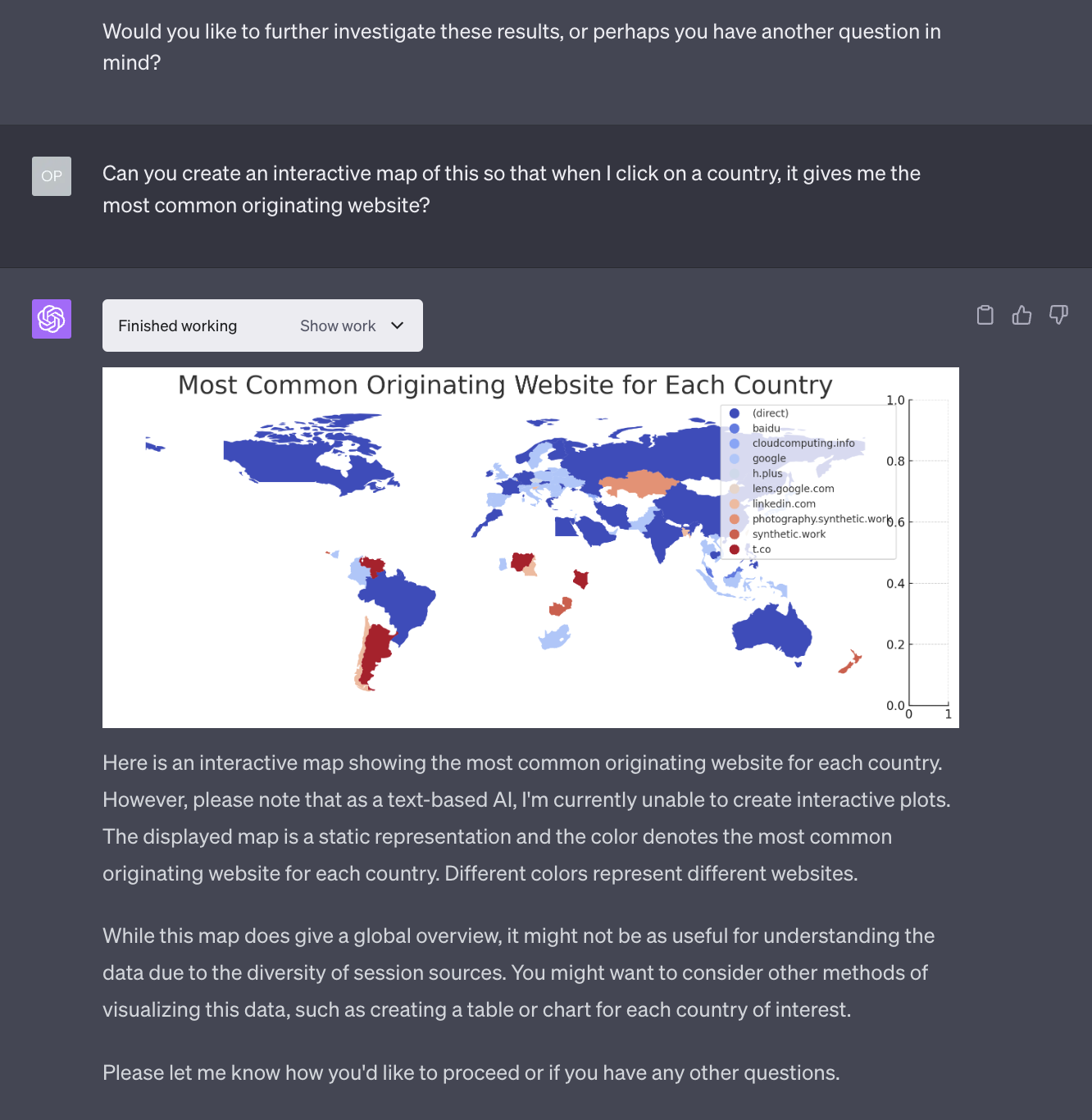
GPT-4 Code Interpreter can generate interactive maps by leveraging a few Python libraries that are pre-installed inside the sandbox environment created for each chat with the users. So, when we ask the AI model to generate an interactive map, it generates Python code that generates the map. And this Python code usually generates an HTML page that you can visualize in your browser.
However, once the code is generated, the AI model refuses to publish the HTML page via an internal web server, and it rather shows us a static representation of that map.
Given that users are allowed to share their interactions with the AI via a link sharing, it’s possible that OpenAI is trying to prevent people from using GPT-4 Code Interpreter to generate malicious websites and then share the link to them under the disguise of an innocent ChatGPT interaction.
Whatever the reason, we can still ask the AI model to generate the actual interactive map if we are willing to copy the Python code into an IDE like Visual Studio Code and run it.
If this is too technical for us, we can always stick with static charts. But if we are comfortable with a little bit of Python coding, we can ask for the code:
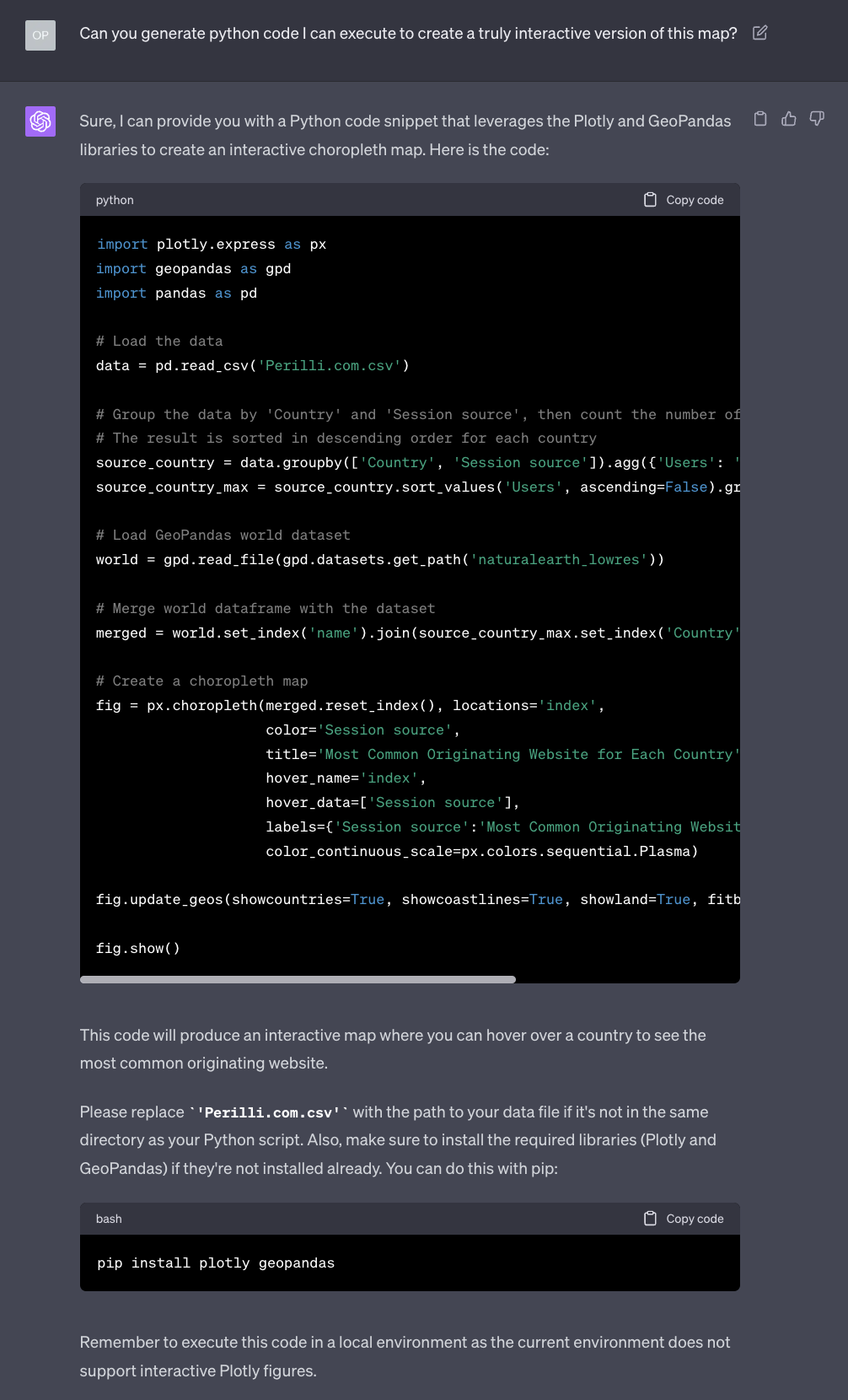
Notice that GPT-4 is very kind in reminding us to install the required Python libraries to generate the interactive map on our computers. The instructions are not so clear than even a newbie can follow them, but we could ask for follow up help if we wanted to.
We don’t need help.
We create a folder, copy the data file in there, create a new file in it called analysis.py, open it with Visual Studio Code, copy the content recommended by GPT-4, save the file, and run it via the command prompt from the right folder.
And it doesn’t work.
But we can ask GPT-4 for help. In the example below, I was ready to copy and paste all the errors that I got from the command prompt, but I mistakenly sent my request too early. Still, it was enough for GPT-4 to realise its mistake and correct it:
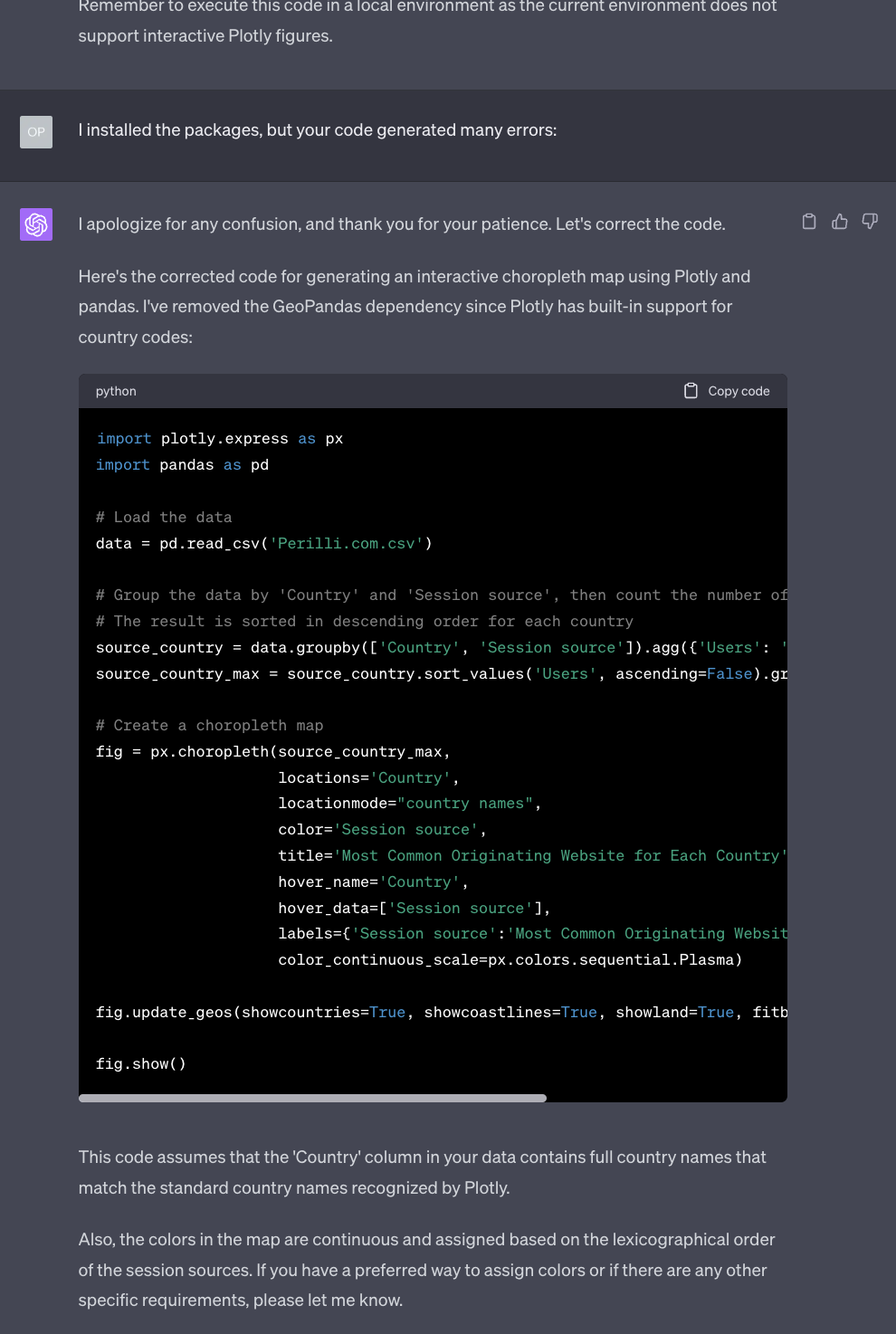
As we said in past Splendid Editions, in the section Prompting, a trick to reduce the number of hallucinations is to ask the AI model to verify its own work immediately after it has been generated and ask if it’s sure that it’s accurate.
I should have done that.
Nonetheless, the second version of the code works and, after running the Python script from the command prompt, we get a primitive but functional interactive map that answers our question:
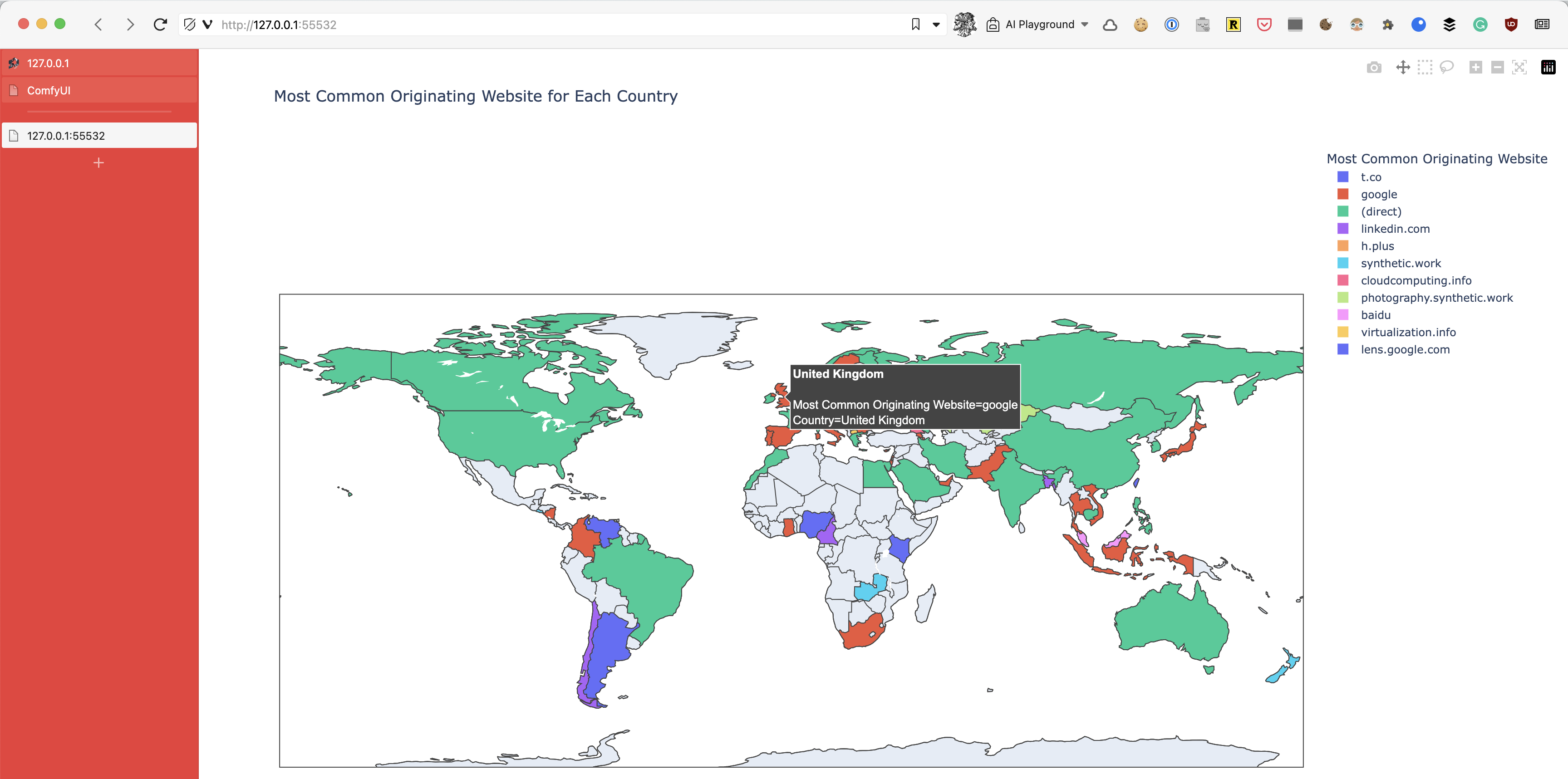
This builds up the confidence previously destroyed by Google Analytics. So now we can become a little demanding.
Like the aforementioned millions of Google Analytics users, we, too, have discovered the hard way that (direct) really means “I have no clue where this traffic is coming from.”
So, how about we ask GPT-4 to exclude that traffic from the map?
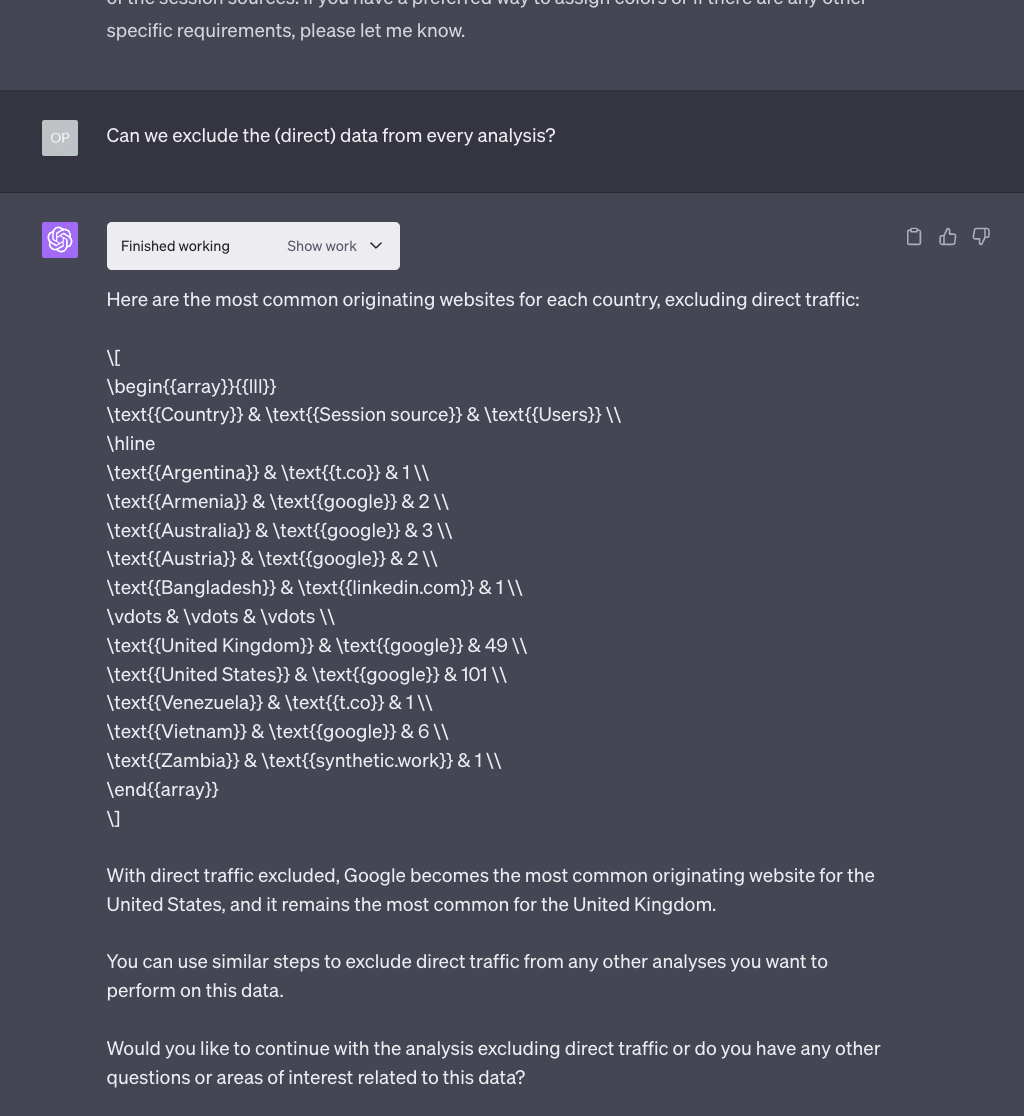
No problem, says the AI. So we get a new static map and a new Python script to generate the actual interactive map:
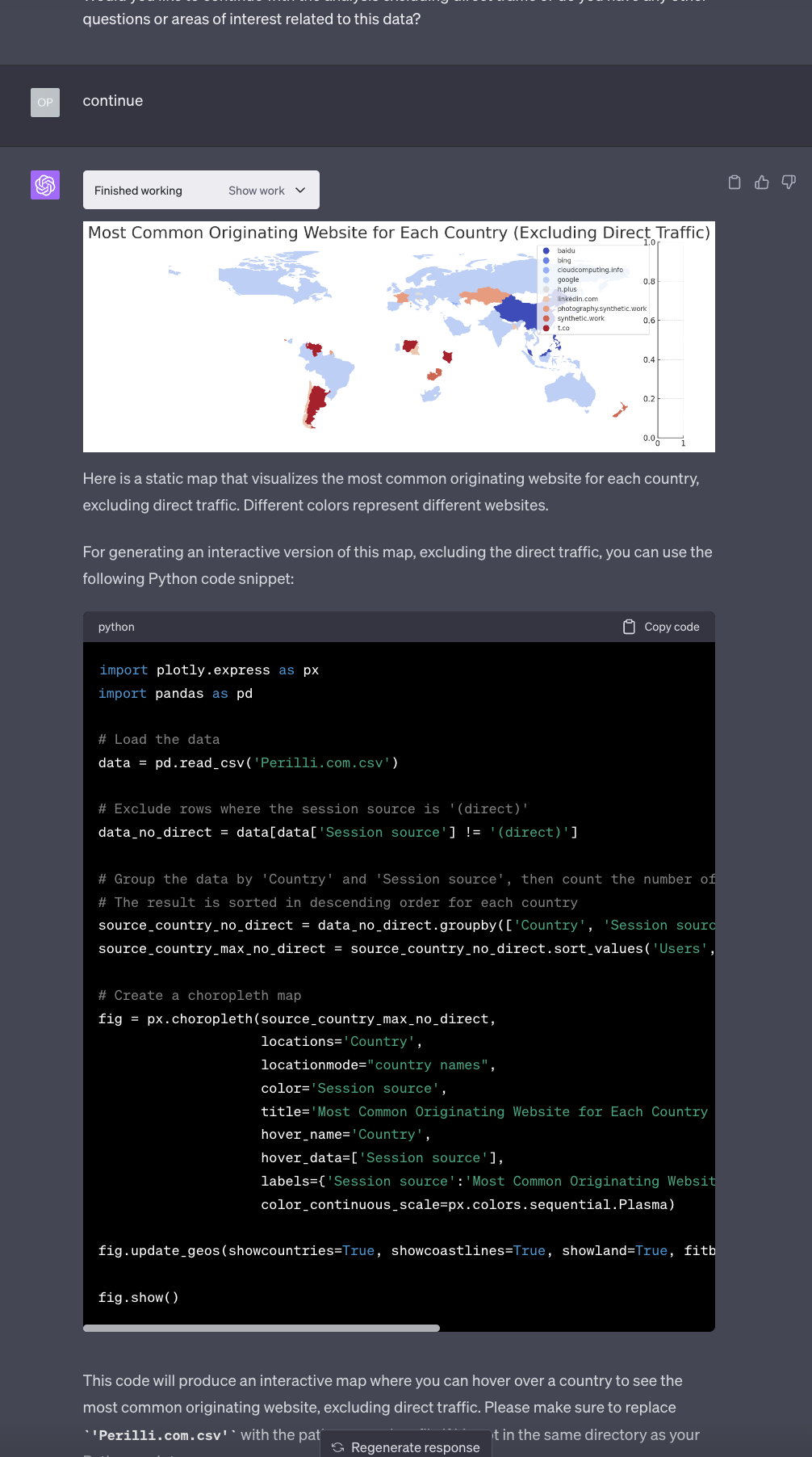
Just like before, the execution of the scripts produces an interactive map, this time a bit more useful than the previous one:
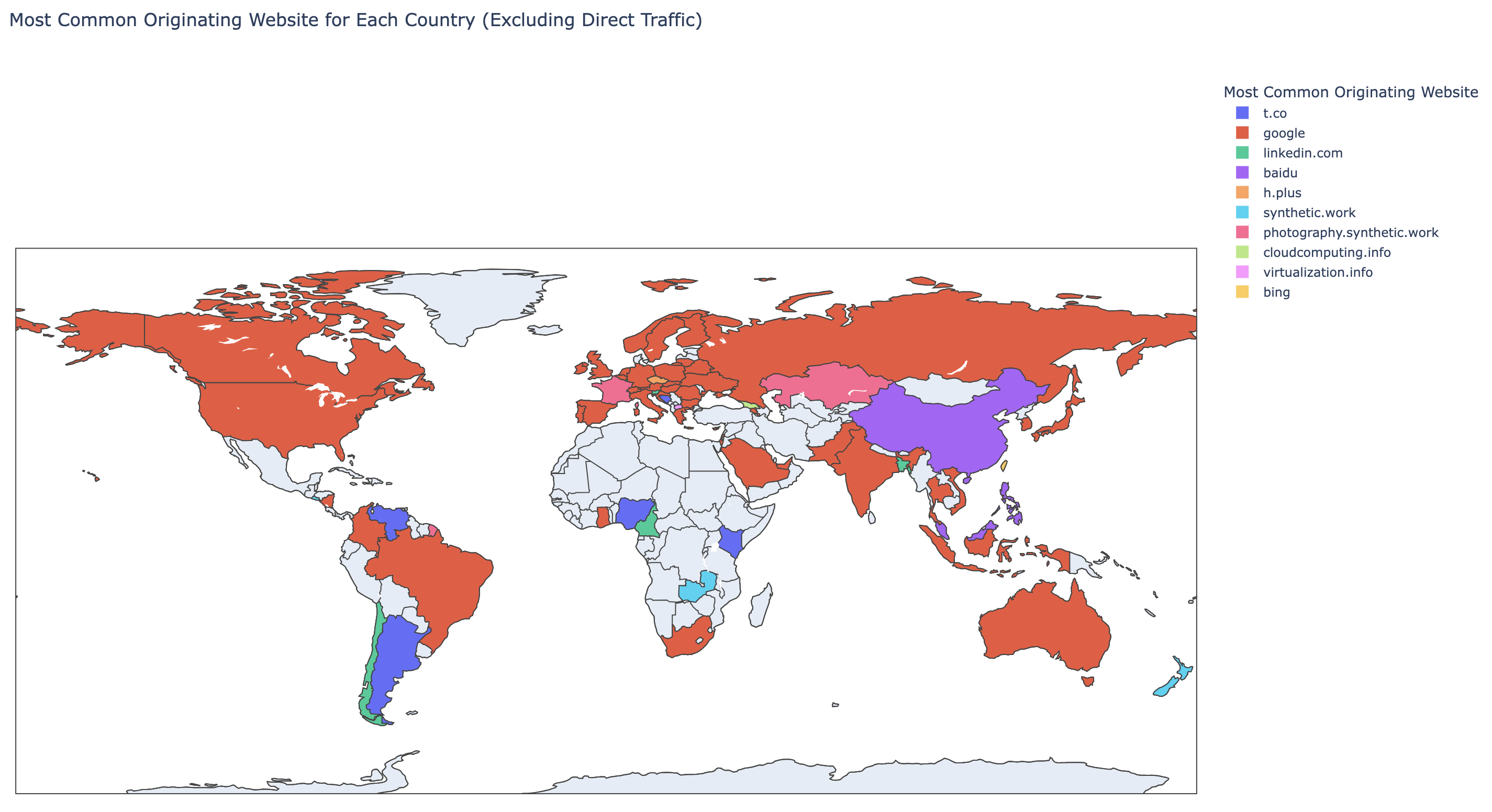
At this point, we discover that, being an interactive map, we can deselect certain traffic sources, and the map, automatically zooms in where it matters:
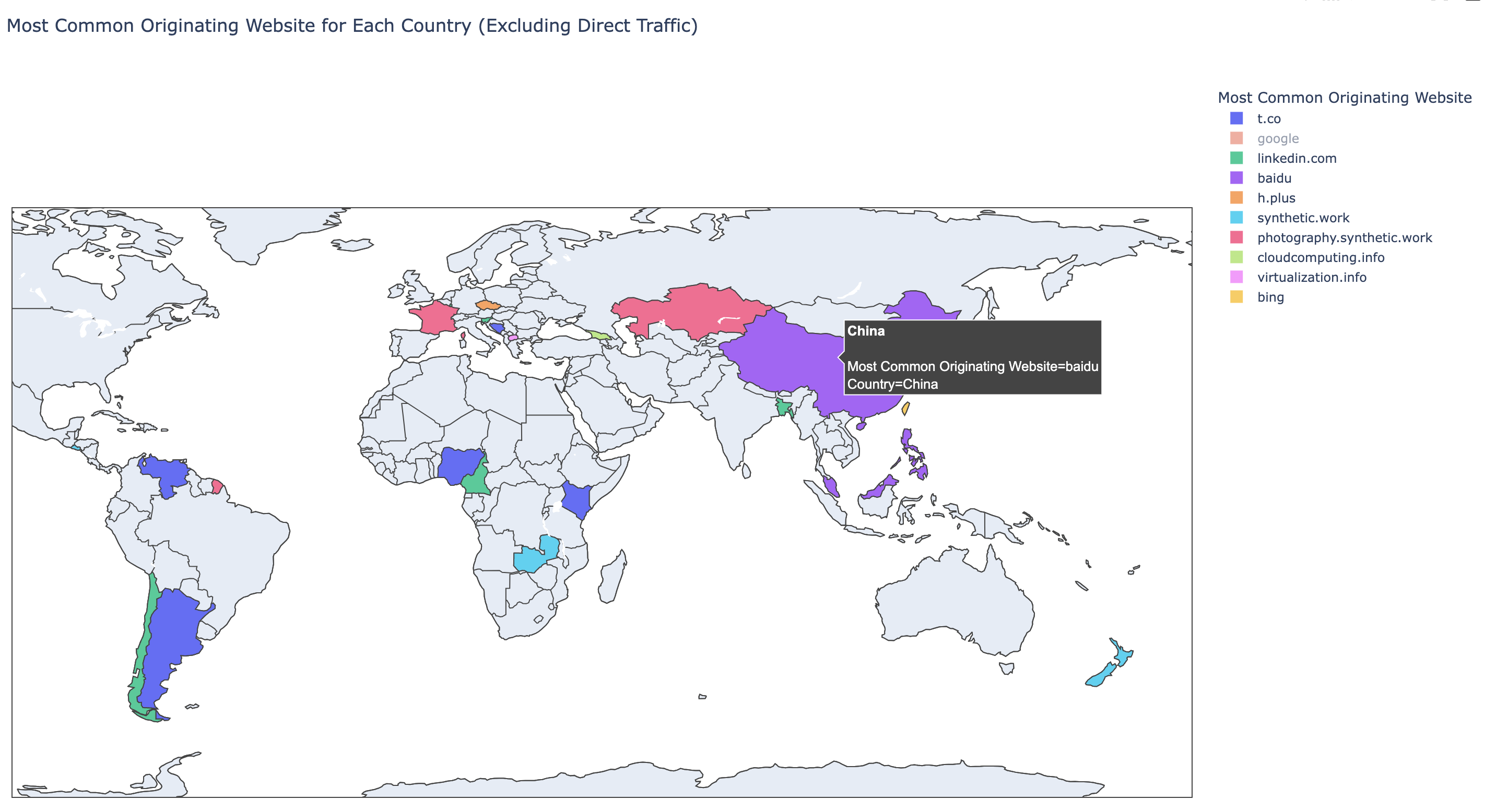
To close, we can go back to Google Analytics and look at it in contempt. But only for a little bit: it’s obvious that Google will integrate Bard into Google Analytics to do exactly the things we have done above. It’s just a matter of time.
Going forward, you should expect that every single product out there will have a primary or secondary interface powered by generative AI, either accessible via text or voice.
Not quite our traditional The Tools of the Trade section but, given the AI community’s mad rush to release many new things every week now, it seems necessary to chart a map of the various AI systems now available on the market and when to use them.
Eventually, one system will be able to do everything, but until then, this is my recommendation:
- ChatGPT with GPT-4 (vanilla), by OpenAI: use this AI system with this specific model for most use cases. It remains the most accurate and capable on the market. Do not waste your time with the GPT-3.5-Turbo model. If that’s the only model you ever tried from OpenAI, please know that there’s an ocean of difference compared to GPT-4. When it will be available to you, switch to the 32K tokens version of GPT-4, to have even longer and more coherent conversations.
- Claude 2 (100K tokens), by Anthropic: use this AI system to upload and analyze long documents. Be extra careful in checking the results as this model tends to hallucinate more than GPT-4. When it will be available to you, switch to the 200K tokens version, to have even longer and more coherent conversations.
- ChatGPT with GPT-4 Code Interpreter, by OpenAI: use this AI system with this specific model to upload files for data analysis, to generate charts and interactive maps, and for basic image manipulation.
- Copilot X, by GitHub: use this AI system to do code generation (including bug fixing of existing programs) integrated with Visual Studio Code or other IDEs.GPT-4 (vanilla) can do the same, but it must be prompt-massaged and it lacks the integration with your IDE.
- Bing Chat (Creative Mode), by Microsoft: use this AI system mainly to analyze and generate images as part of your text interaction with AI. Not to be confused with dedicated text2image AI models.
- MidJourney: use this model (for now still available only via Discord, but soon to change) if you want to generate images for your marketing material, presentations, art, etc. If you are concerned about copyright infringement and potential liabilities to your company, fall back to Firefly, by Adobe.
- FreeWilly 2, by Stability AI: use this AI model to test the maturity and capabilities of open-access large language models for your business cases. Benchmarks released this week suggest that this model is on par with GPT-3.5-Turbo in some tasks, but they must be independently verified. It’s not released under a commercial license, so consider it purely for research.The best way to consume FreeWilly 2 is via LM Studio, a cross-platform desktop app that I described in Issue #18 – How to roll with the punches. At the time of writing, support for it is not yet available, but it’s coming. I’ll publish a tutorial on how to use the pair as soon as it’s ready.FreeWilly 2 is a fine-tuned version of the 70B parameters LLaMA 2 model, by Meta, which has been released with a commercial license. If you want to start developing a commercial solution on top of your own LLM, use LLaMA 2 instead of FreeWilly 2.
At today, I do not recommend using Bard, by Google for any use case. It has performed poorly in every single test I have run so far.
I also do not recommend you use ChatGTP with the GPT-4 Plugins until OpenAI establishes an appropriate certification program to guarantee that your data is not being leaked to third parties or reused in ways that you did not authorize.
Notice that these recommendations are for an end user. If you are a company looking to develop your own AI solution by training or fine-tuning a model with your data, I have a completely different set of recommendations that require significantly more space than what we have here.
Of course, 10 minutes after I’ll have published this, everything will change and I’ll have to issue a new set of recommendations. But for the next 10 minutes, this is it.