
- The ten AI-first products I use on daily basis
- How to compare the AI models from A12 Labs, Anthropic, Cohere, Eleuther AI, Google, Meta, OpenAI, etc.
- How I use GPT-4 Plus to do things I am crap at (and how it feels like being in an Iron Man movie)
- What’s the job-to-be-done of a chatbot/assistant? And where do people feel more natural to find it?
- How I used Perplexity AI to do things I am not crap at, but I don’t have time to do
- Do we need bigger AI models or better prompt engineering skills?
- What does it mean for an AI company to compete against OpenAI? And for how long is it sustainable?
- How much money will you be happy to pay for GPT-22?
This week we are going to do something very different from the usual.
So far, the Splendid Edition of Synthetic Work offered an in-depth review of how AI is impacting each industry of our economy.
For example, Issue #2 was dedicated to the Legal industry: Law firms’ morale at an all-time high now that they can use AI to generate evil plans to charge customers more money
Issue #4 was dedicated to the Health Care industry: Medical AI to open new hospital in the metaverse to assist (human) ex doctors affected by severe depression
And, gloriously, Issue #1 was dedicated to the Education industry: Burn the books, ban AI. Screwed teachers: Middle Ages are so sexy.
This type of content goes in a section of the Splendid Edition called “Screwed Industries”. We’ll resume that programming soon.
But there’s another section I mentioned in Issue #0 that we have yet to use: If Your Only Tool is a Hammer…
The logic behind that section is that it’s incredibly important to understand how AI is transforming the way we work across these industries, regardless of our line of work. What AI-first tools that are replacing existing software and services, redefining market shares and productivity.
So today we talk about the AI-first tools that I personally use on daily basis.
This is not a list of AI tools I never heard of that I’m passing to you for consideration. A list of blurbs written by copying and pasting from some product descriptions.
My work depends on these tools. I know them intimately. And I’m vouching for them by describing them in this Splendid Edition. Which is very uncommon: I rarely recommend anything to people.
As an individual, you might want to give these tools a go, perhaps to boost your productivity and stand out compared to your coworkers at the office.
As an organization, especially if you represent a technology vendor, you might want to think if there’s an opportunity to productize some of these products, commercialize them via OEM agreements, or replicate them, adapting their capabilities to target the audience you intend to reach (e.g., large enterprises).
As a former tech executive in charge of business and product strategy, what I’ll say below about these tools is wildly different from what you’d read in press articles. And talking about the tools is an excuse to talk many other things like product strategy, competition, and user experience.
All of this is to say that I was bored with writing about specific industries and wanted a break.
There. I said it.
Happy now?
Alessandro
Here’s the list of the tools we’ll talk about, organized according to what I use the most or what I consider most important for my workflow as a knowledge worker and a creator (like Jesus, but with shorter hair and more followers):
- GPT-4
- Perplexity
- Prompt+
- Descript
- Fig
- Uncanny Automator Pro
- Stable Diffusion
- Pixelmator Pro
- 11Labs
- Grammarly
I actually wanted to list these tools in alphabetic order to mitigate any bias, but then I thought that it would have defeated the purpose of this newsletter: understand how our work is changing and how our perception of what’s important is dramatically shifting.
I don’t think you, dear reader, have the patience to go through this list in one go, so today we talk about the first two.
GPT-4
I’m not going to tell you what GPT-4 is or what it does, but I’m going to tell you this:
I’ve tried every large language model (LLM) ever released, including the most obscure or the most unfinished. I usually test them before most people on the planet.
Some of them, I have running on my personal computer (an Apple MacBook Pro 2023 with the M2 Max CPU and 96GB of RAM), like for example LLaMA, which was released by Meta AI towards the end of February.
Others, which require much more powerful hardware, I have tested in dedicated sandboxes provided by the AI startups that train these models, or by generous third parties like Nat Friedman, who, for a period, offered an online playground where to compare them:

At some point in the future, I’ll have to consider buying a desktop-class machine with a some NVIDIA GPUs to do more advanced experiments and fine-tune the models, but it’s not yet necessary.
I just want you to know that if, completely by accident, I unlock Artificial General Intelligence (AGI) and I wipe out humanity, I accept no responsibility. The blame will be assigned to the IT vendor that has provided the hardware.
But I’m digressing. Back to the point:
I’ve tested AI models from A12 Labs, Anthropic, Cohere, Eleuther AI, Google, Meta (including the fine-tuned versions offered by Stanford University called Alpaca), OpenAI, Salesforce, and many others. As I type this, the public release of Open Assistant, an open source chatbot sponsored by the famous AI organization LAION, has come to life.
None of these comes even remotely close to the experience that OpenAI GPT-4 offers.
This experience I’m talking about will be the key to unlocking mass adoption and planetary-scale profits, but to explain it, I need to take a step back and tell you how I use GPT-4.
First of all, I only recently decided to pay for the $20/month subscription that OpenAI calls Plus. Yes, my eyes are rolling so hard they might leave the orbit.
The reason why I decided to upgrade from the free experience is that OpenAI has recently announced a plug-in system, effectively evolving its approach from an AI-as-a-service company to an AI platform company.
As I commented at the time of the announcement:
Of course OpenAI is enabling plug-ins. They are not just building AI-as-service. They are building an AI platform. An automation hub with an artificial brain at the center. Imagine Zapier (to which they connect), but with GPT-x as central node.
— Alessandro Perilli ✍️ Synthetic Work 🇺🇦 (@giano) March 23, 2023
More from that thread (too awkward to link to every tweet):
The AI sees everything, moves everything, decides everything.The @OpenAI plugin approach, which will be certainly followed by other companies offering AI foundation models, will represent a huge threat to those companies that have a business model based on offering support on top of open source technologies.These companies used to say “Do you really want your business to depend on your employees doing a google search?”. They can’t anymore.
While it’s true that large language models still make significant factual errors, this is going to decrease more and more.Plus, the infinite number of plugins that we are about to see, will create the context for the LLMs to do fewer mistakes, and will give AI access to information and knowledge that will enormously enrich the answer.On top of all the critical answers you need, we’ve already seen GPT-4 and the new Copilot X create pull requests for you in an automatic way for buggy software.Employees using these types of AI will see less and less reason to justify a support-based business model because they will get all the support they need from the AI.This might be a fatal blow. Especially for those companies that have been sleeping while AI was emerging, that have no in-house expertise, and that have a huge gap to fill.
With all of this in mind, you can understand why I want to test this new plug-in system that OpenAI has unveiled. And the fastest way to do it is by subscribing the Plus version of GPT-4.
I don’t have yet access, though. And so how am I using GPT-4 until then? Let’s make an example which will close the loop and bring us back to this feeling that I keep mentioning.
As some of you know, I have recently disclosed that I’ve founded a company: Unstable Reality.
For its stealth mode website, I wanted to achieve a particular effect which requires the capability to write Javascript code.
The problem is that I’m not a software (and, like me, billions). So, in a situation like this, I’d normally have three choices:
- I set up a WordPress website (long to do, even if I have 20 years of experience) and buy a plug-in that gives me the effect I want to achieve without technical expertise (expensive)
- I pay someone to do the job (I refuse to even if it’s cheap, it’s a matter of principle)
- I spend hours on Google and Stack Overflow to find the solution (long, and very expensive if you value your time, but at least you learn new things)
My usual route is #3. That’s how I learned a lot of things that have absolutely nothing to do with my job. But, every time I followed route #3, I had to believe that I would not be completely miserable along the way.
If the perceived cognitive friction of #3 seems insurmountable, even the most determined learner would be deterred. And I really didn’t look forward to learning Javascript just to set up a homepage.
So I asked GPT-4.
Because I am not a programmer, if the code GPT-4 recommended to me didn’t work, my only way out was to complain about it and show it what errors I got from the browser.
This trial-and-error approach led to an hours-long interaction with the AI to achieve something that a programmer would probably have done in 10 minutes.
In the end, I obtain what I wanted but, GPT-4 and I had to explore three different approaches to get the result. Two of them were suggested by the AI, and one was suggested by me after I learned about the first two.
I don’t know if I would have saved time by using Google and Stack Overflow. I suspect not. But what matters is how I felt during the process, and this is THE THING you should really think about when you read Synthetic Work.
Never wrote a line of Javascript in my life. Today, I had to. If I’d have used my usual approach, I’d have spent hours on Google & Stack Overflow. Instead, I asked GPT-4. I still spent hours, but I worked back & forth with the AI to arrive to a solution and I learned a ton.
For a software developer, this is nothing to pay attention to. But for a person that doesn’t code, this is a transformative experience (I already had it with Copilot for some Python code). The sense of empowerment that comes from it is impossible to explain.This is the real revolution of generative AI: not what you can do with it, but how you feel when you do things with it, and the sense of possiblity that you have after you used it. It really feels like you are talking to a primitive version of JARVIS in Iron Man movies.GPT-4 is not perfect, and I definitely look forward to the 32K context window, but you leave thinking “it doesn’t matter if it’s imperfect. I can already do more than I ever hoped I would. It will get better.”AI startups targeting non-technical people need to focus on how their product makes you feel, not just what it does. That is the message that will make the audience look and yet, no attention has been spent on that.
Notice that I did not use GitHub Copilot for this job.
I have access to it, as well, and Copilot lives in the software that most people use to write code, me included: Visual Studio Code.
The most natural thing to do was to open a new file in Visual Studio Code and write in plain English the things I wanted in my webpage. Yet, I didn’t.
Why?
I did not do it not because the version of Copilot I have access to doesn’t rely on GPT-4 yet (I will when GitHub will accept my request to join the new Copilot X program). The thought didn’t even occur to me until later.
Perhaps, I didn’t do it because, not being a software developer, using Visual Studio Code or another integrated development environment (IDE) is not my second nature. But it’s also possible that I didn’t do it because the idea of an assistant is seeding in my mind and, in my mind, a general-purpose assistant doesn’t live inside a special-purpose program like Visual Studio Code.
I believe this is a very important consideration for those companies that are planning to offer a large language model or are already doing so.
As they use AR/PR, marketing, and sales to attempt to establish the job-to-be-done in the mind of their customers, these companies also have to think how that job-to-be-done will influence where customers feel more natural to find the AI.
Imagine this:
Office workers are exposed to 20 different AIs, offered by 20 different companies, one in each product used by the office workers.
Collectively, these companies succeed in convincing the office workers that artificial intelligence is valuable and should become part of their daily life. But only one of those companies manages to establish a very precise job-to-be-done in the mind of those office workers. And that company’s AI lives in the browser.
So where will those office workers feel more natural to go to use AI?
Perhaps, they will use AI wherever it is. Perhaps, like me, they will insist on going back to the browser. And if that’s the case, the other 19 AI companies in my example have a big problem in terms of competition.
If you need cash urgently, you are going to use the first ATM machine you can find. Even if it’s located inside a pigsty. But if you are not in hurry, are you really going to take cash in that pigsty?
Let’s try. Close your eyes. I want you to be in that pigsty now.
Be there.
Feel the experience.
Take it all in.
Now, tell me again you are going to use that ATM machine.

This problem is not limited to the B2C side of the market. If your company offers enterprise-class applications and you are super-powering them with a large language model as we speak, you have exactly the same identical problem.
The dilemma of where users look for their AI will present itself over and over, as users discover and familiarize themselves with more use cases where large language models are not a complete waste of time.
Multiple Synthetic Work readers have asked to see some practical guidance on how to use GPT-4 and other large language models to do their daily office job in the most effective way.
They have reported feeling lost in front of the OpenAI blank canvas that in theory could do anything but in practice does nothing until you ask.
I’m planning a special edition of Synthetic Work all dedicated to prompt engineering to help these readers.
Until then, we have another tool to look at today.
Perplexity
Differently from GPT-4, this tool requires an explanation.
Perplexity AI is a startup founded by some of the brightest minds in the AI community. OpenAI, Meta AI, NVIDIA, Quora, Palantir, Coursera. You name it.
What these guys have done is constrain a large language model with prompt engineering and other techniques so that the AI is really good at one specific task: questions and answers.
At some point in time, they used OpenAI GPT-3 as the underlying AI model, but they are not disclosing if it’s still the case or they switched to something else.
Their constrained LLM initially came in the form of a browser extension, and that’s how I mainly use it. Now it’s also available as an app for iOS, very recently released.
Both the browser extension and the iPhone app are free for now.
How do I use it?
The most valuable use case for me is using it to answer specific questions about a long web page or an academic paper (of which I have to read dozens every week).
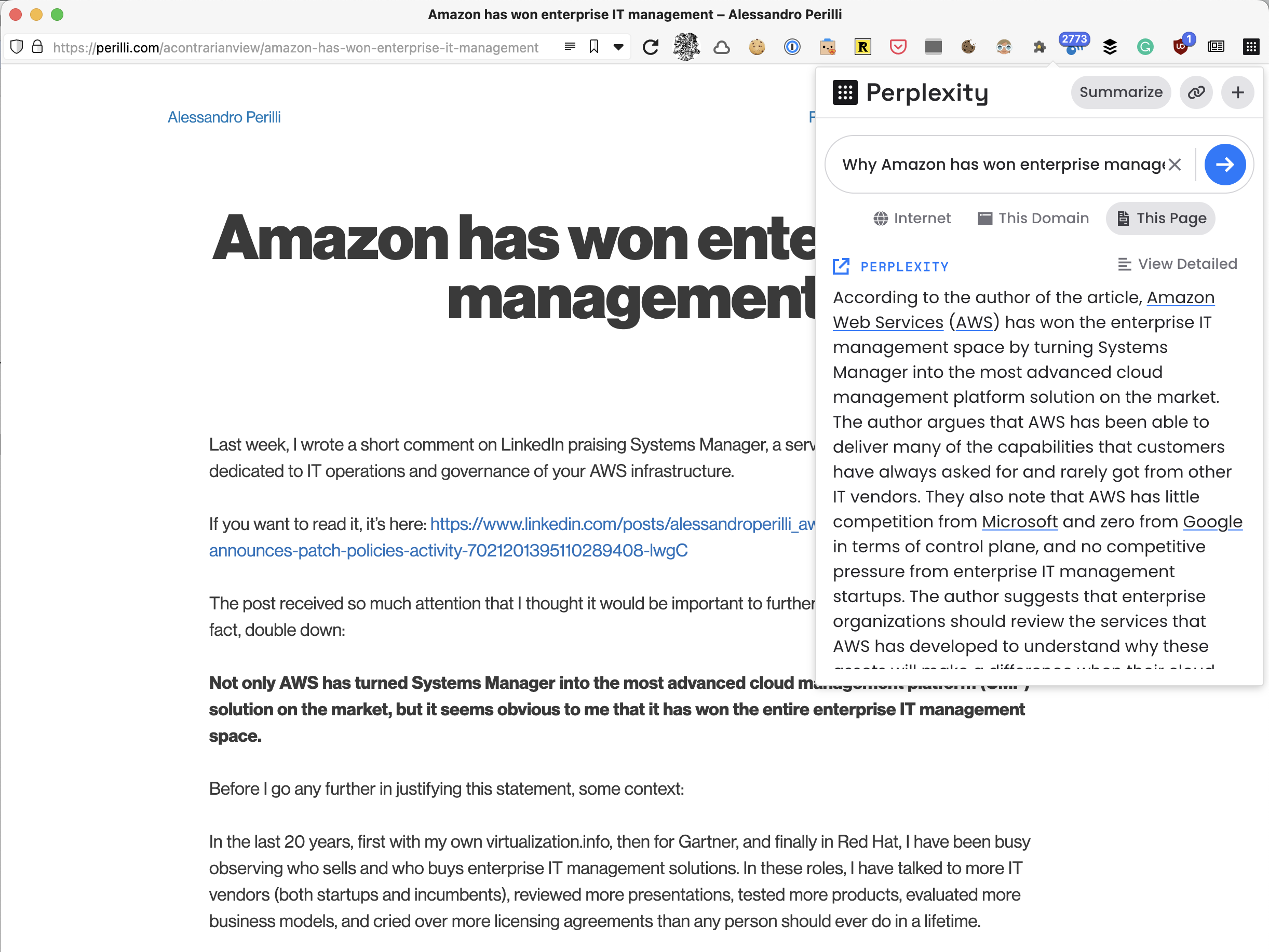
Let’s use it on my own material (something I never tested before writing this newsletter): a long blog post I wrote after leaving Red Hat titled Amazon has won enterprise IT management.
Perplexity does an outstanding job at summarizing my thinking:
But where Perplexity really shines is when you adjust the scope of the Q&A session.
In the previous screenshot, you’ll notice that I’ve indicated only the specific page I was browsing as the scope of my request. As result, the AI knows nothing about me and calls me “the author”.
When I change the scope of my request to the entire perilli.com domain, all of a sudden Perplexity knows who I am and connects what I wrote in this specific blog post with other blog posts and with my entire Twitter archive which I backup on perilli.com.
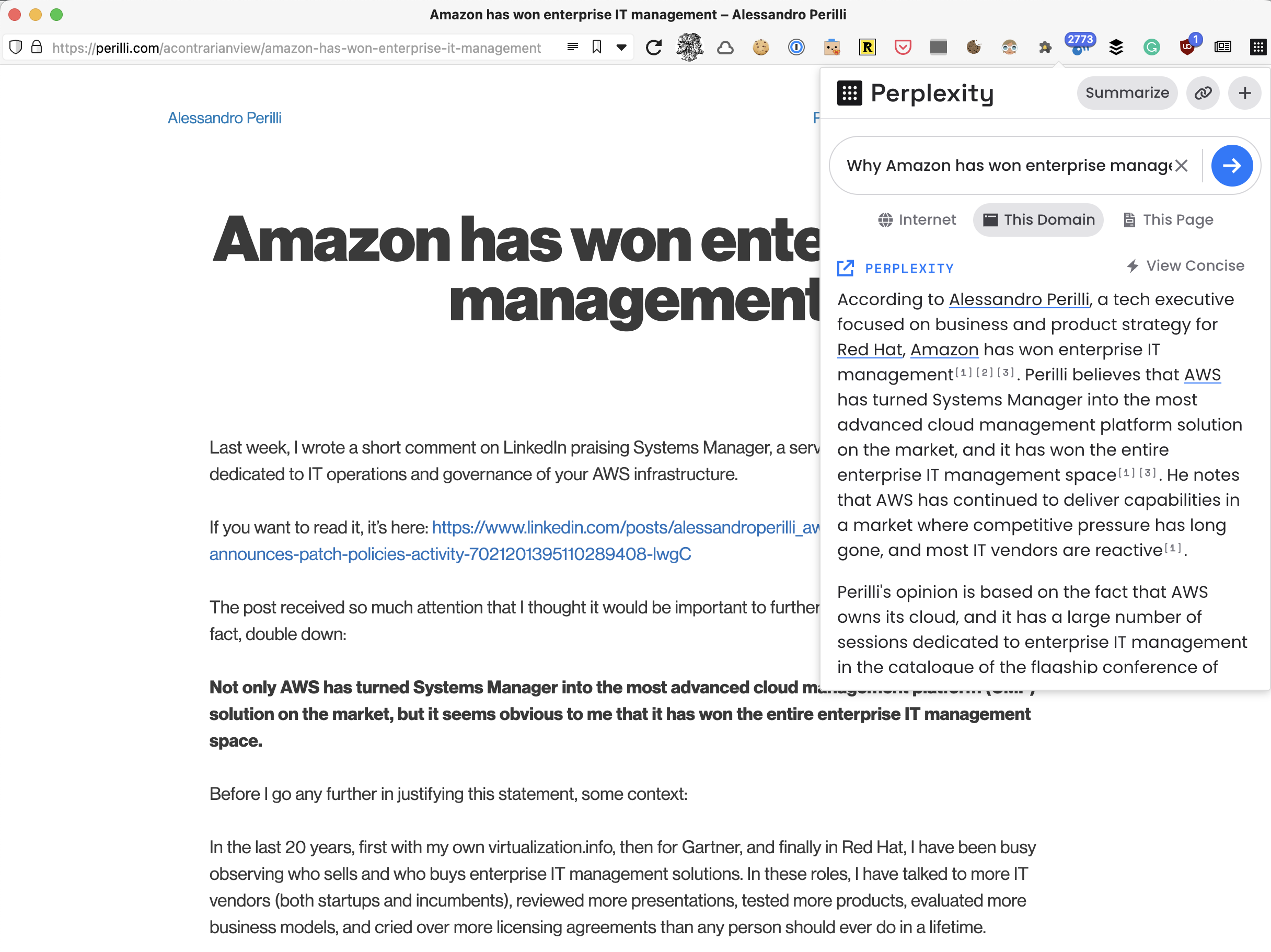
Like every other large language model, Perplexity is not perfect. The wider the scope, the higher the chances the AI will connect things there are not really related.
Also, Perplexity doesn’t eliminate the need to read the original material, but at least can give you the gist of it so you can quickly assess if it’s worth further analysis or not.
So far, the most advanced use of Perplexity I’ve seen tested on is the analysis of academic papers and other technical documentation, amply documented by Aaron Tay, librarian at the Singapore Management University.
In the same fashion, you could use Perplexity to summarize this incredibly long and mortally boring newsletter. You would not suffer, and suffering it the experience you are paying for, but you could go to the gym earlier.
As Aaron demonstrated in his review once again, prompt engineering skills are critical to obtain what we want. Which is exactly what we do in real life.
I hope you are seated:
When we asked somebody to do something for us, we succeed or fail depending on how good our “prompt” is.
Now you cannot unsee the truth.
Which reminds me of a statement made at the beginning of the week by the famous AI researcher Andrej Karpathy (a cofounder of OpenAI):
Expectation: I need more deep learning engineers to train better models
Reality: You need prompt engineers and LLM Ops (not sure what to call it (?), post-LLM above-API infra, langchain & friends)
– training is centralizing into megamodels
– not fully played out yet but trending— Andrej Karpathy (@karpathy) April 3, 2023
In other words, the imperfect answers of the AI models we have today can be fixed with better prompt conditioning rather with larger/more powerful models.
Which leads us to two questions:
- Could I use GPT-4 to do what I do with Perplexity?
- Has Perplexity (or any other company) a competitive advantage that can defend?
The answer to the first question is: probably. The problem is that there’s an immense amount of friction in copying and pasting a webpage into the OpenAI GPT-4 interface.
I might well think that the job-to-be-done for an AI is better done in the OpenAI UI by GPT-4, but I’d rather stay within the system I’m in if that job requires me too much effort. Which is another consideration critical for those companies that are thinking about super-powering their products with AI.
Of course, things changes if OpenAI releases a GPT-4 browser extension. Which leads us to the second question.
And the answer to the second question is: probably not.
Nothing stops OpenAI from launching a browser extension and a series of apps for every mobile platform and gaming console out there. If they do it, Perplexity AI will have to show that they can do a much, much better job with the Q&A use case than OpenAI.
There is another possibility: OpenAI does not launch a browser extension and a wide range of apps.
Any company that wants to establish itself as a platform company operates around a fundamental tension between two conflicting needs:
- On one side, there is the need to create an ecosystem of partners that can reliably build a business on top of the technical foundation that the platform company offers.This is especially convenient when a company starts, as it lacks the time and resources to deliver production-quality features for every use case.The more your ecosystem grows, the bigger the trust partners place in your platform, the healthier is your business.
- On the other side, there is the need to address the customer demand to provide a certain set of platform capabilities out of the box.Customers don’t want to rely on a single third party for a critical functionality, especially if it’s poorly integrated or overpriced. In part, it’s a problem of having to deal with multiple entities to support a single scenario.
In part, it’s poor leverage in deal negotiation.And so, sooner or later, platform companies find themselves in the difficult position of cannibalizing their own ecosystem by delivering out-of-the-box capabilities that are very similar or identical to the ones offered by their partners.
Every platform company has to deal with this tension, and when it does, it normally screws things up. We have seen it both in the B2C and in the B2B markets with Microsoft, VMware, Amazon, Apple, and many others.
In the Apple ecosystem this problem is so famous that the community even gave a name to it: your product has been Sherlocked.
At least in this phase of their lifecycle, OpenAI might decide that it’s more convenient to let companies like Perplexity AI to thrive as partners rather than trying to offer everything for every use case.
Of course, nothing stops a random dude called Alessandro from writing a browser extension (with GPT-4!) that calls the GPT-4 API and compete directly against Perplexity. If the random dude Alessandro knows a thing or two about prompt engineering (he does), he might even have a chance.
And while this is a fundamentally different type of competitive scenario, it serves the purpose of reminding another point I made years ago (and can’t find because of the horrific Twitter search engine):
This is a unique moment in the history of our economy where, thanks to AI, a startup of 5 can compete against a large, established market player.
The cost of training AI has become prohibitive due to the resource-intensive machine learning approach we insist on using. Almost nobody on the planet has the skills and the resources to train an AI model bigger than GPT-4. This might change for a couple of reasons, but until then, a startup of five can still innovate on top of the GPT-4 APIs.
For a little bit.
Until they get Sherlocked.
And you and I find ourselves addicted to an array of AI-first tools that have enormously improved our quality of life and boosted our productivity, and that eventually get all replaced by OpenAI GPT-22.
We are about to see a supernova of AI-powered innovation where my 10 tools will probably be replaced by a 100 much better ones. And then we’ll likely an implosion leaving us with very few winners and a ChatGPT that costs as much as an iPhone:
If you're willing to pay $42/month for #chatGTP, which is highly imperfect as the entire planet rushed to point out, how much would you pay for an #AI that is as amazing as the one in the movie "Her"?
If the price increase is gradual, I bet people would pay as much as an iPhone.
— Alessandro Perilli ✍️ Synthetic Work 🇺🇦 (@giano) January 22, 2023
The only thing that can counterbalance this is the advent of those open source large language models that Stability AI and others are preparing to release.
Once they are out, it will be up to large vendors that want to compete against Microsoft and OpenAI to customize, productize, and sell those models at planetary scale. So that we all have a fair market.
Oh crap, I was supposed to talk about the tools…