
- Students don’t feel too reassured about their future in a world powered by AI. If only they could read Marc Andreessen’s blog posts…
- A Stanford professor and a former Google PM make the case that companies must be much bolder than in the past to avoid mass unemployment due to AI.
- GitHub publishes an interesting update on the adoption of Copilot and attempts a calculation of the economic impact of AI-powered software development.
- People working for Amazon Mechanical Turk and cutting corners with AI might be contributing to a dreadful-sounding phenomenon called “Model Collapse”.
- Outset.ai is the latest startup promising to make research a walk in the park. What could go wrong?
P.s.: This week’s Splendid Edition is titled How to turn Visual Studio Code into the ultimate writing tool for people that don’t write a single line of code.
In it, you’ll read exactly that: a very long explanation of how I have set up Visual Studio Code to boost my writing to unprecedented speed thanks to Copilot and many other extensions.
This issue is strictly for non-technical people.
A warm welcome to the wave of new members of Synthetic Work. You start to be a lot.
I’m amazed by the variety of industries that you all represent. Among you there are leaders and innovators in almost every industry, from education to financial services, from consumer electronics to retail, from energy to technology, from government to non-profit.
It’s the kind of diversity that I hoped Synthetic Work would attract since the day I launched this project five months ago.
Don’t forget that, if you want, the Explorer or Sage membership of Synthetic Work gives you access to a Discord server where you can get in touch with other members in your same industry or in other industries.
There’s a lot to be learned from each other if you overcome the shyness.
Lots of things are happening behind the scene: new tools being made, collaboration with top AI researchers, consulting with some of the most forward-looking companies on the market, sponsorship conversations, and more.
I’ve also started a long journey to attempt to create a synthetic clone of myself, fine-tuning a large language model on over 10 years of material I’ve written on a daily basis.
I have reasons to attempt this experiment, but it’s too early to talk about it. Let’s first see if it works.
Wish me failure.
Alessandro
The first thing you might want to focus your attention on this week is an article on students’ feelings about their future in a world powered by AI.
Clea Skopeliti, reporting for the Guardian:
Ronan Carolan has always been the creative type, and after attending an art school’s open day last autumn he thought he had settled on illustration as a degree.
But as the Ucas deadline approached, he began to have second thoughts. “I noticed more and more things drawn by AI,” he says, referring to a magazine cover among other examples. “Considering that only a few years ago, the images it generated were entirely nonsensical, it is scary how fast it has progressed.”
Carolan, who is 18 and has just completed an art foundation course in Cardiff, decided architecture would be a safer path to follow. “It feels like it will be a more secure degree. Lots of psychology goes into architecture,” he says. “You need to understand the core of what you’re doing.”
“The options will probably get limited as time goes on. Personally, I’d find it a bit depressing if there wasn’t a human element, but whether or not we’d notice I’m not sure. I always thought things like art would be one of the last things robots would be able to do.”
…
Dave Cordle, a career development professional in Surrey, said that many of the young people he speaks to are concerned about the impact of AI on their work futures. “Because of the publicity around ChatGPT, it is planted firmly in the minds of young people.”
…
Elizabeth Lund, a master’s student in translation in Edinburgh, says she is lucky because she believes her preferred niche is likely to be least affected by the expansion of AI. “Literary translation is most resilient as I think publishers see the merit of having human translation. I was most interested in this, and this has solidified my choice.”
…
The use of machine learning in this field is hardly new, but the breakneck pace at which it is improving is worrying, Lund says: “With the advent of ChatGPT, the future is bleak.”
Granted, these are just three cherry-picked examples, and the press always prefers to paint a bleak situation as negativity sells. But people are starting to realize that AI is impacting their chances to find employment unless they go into software engineering and learn how to build AI systems.
Consider the progress made by diffusion models (like Stable Diffusion or MidJourney) and the progress made by transformers models (like GPT-4 or LLaMA) in the last 12 months. Straight from a sci-fi movie.
Twelve months ago there was almost nothing and today, I’m writing this newsletter at super-speed thanks to the GPT-4 model inside Copilot. If you don’t know what I’m talking about, go back and read the introduction of Issue #16 – Discover Your True Vocation With AI: The Dog Walker. It’s really important.
Now imagine a student who just started a 3-year degree in whichever field he/she likes. What will have changed in three years? How about five?
There’s no question that young humans are highly adaptable and will embrace AI in whichever field they decide to work in. But you have to admit that it’s quite unsettling and scary for a young person to realize that the world the school is preparing them for might not be there once they graduate.
More than the fear of not finding a job, I think students are growing a feeling of inadequacy and irrelevance about what they learn in school.
Even when a student looks at AI as a world of possibilities, perhaps especially in that case, he/she might think: “What am I doing here? Why am I not learning this stuff?”
If you are an educator and you are sharing these concerns, I’d love to help. I’d be happy to talk to your students and the teachers (for free, of course), in person or online, about all of this. Just reply to this email.
The second thing that you might want to focus on is an article suggesting that companies must be much bolder than in the past to avoid mass unemployment due to AI.
Behnam Tabrizi, a professor at Stanford University’s Department of Management Science and Engineering, and Babak Pahlavan, a former Senior Director of Product Management at Google, writing for Harvard Business Review:
Compare AI with the rise of electricity around the turn of the twentieth century. It took factories decades to switch from steam-powered central driveshafts to electric motors for each machine. They had to reorganize their layout in order to take advantage of the new electric technology. The process happened slowly enough that the economy had time to adjust, only new factories adopting the motors at first. As electricity created new jobs, laid-off workers in steam-powered factories could move over. Greater wealth created entirely new industries to engage workers, along with higher expectations.
Something similar happened with the spread of computing in the middle of the twentieth century. It went at a faster pace than electrification, but was still slow enough to prevent mass unemployment.
AI is different because companies are integrating it into their operations so quickly that job losses are likely to mount before the gains arrive.
…
Some companies are rapidly integrating generative AI into their systems, not just to automate tasks, but to empower employees to do more than they could before — i.e., making them more productive. A radical redesign of corporate processes could spark all sorts of new value creation. If many companies do this, then as a society we’ll generate enough new jobs to escape the short-term displacement trap.But will they? Even the least aggressive company tends to be pretty good about cutting costs. Innovation, however, is another matter.
Invaluable point. Companies, which are made of people, find it much easier to cut costs than to innovate.
Innovation requires creativity, the capability to think long-term, the courage to take risks and have contrarian views, and a keen focus on execution. I rarely found these qualities in the large enterprises I worked with in the last 23 years.
There are pockets of innovators everywhere but, in my experience, most people lack these traits. Cutting costs is infinitely easier for them.
Let’s continue:
What set the agile, innovative companies apart from those who remained neutral or defensive? The team narrowed the differentiators down to eight drivers of agile innovation: existential purpose, obsession with what customers want, a Pygmalion-style influence over colleagues, a startup mindset even after scaling up, a bias for boldness, radical collaboration, the readiness to control tempo, and operating bimodally. Most leaders praise those attributes, but it turns out it’s remarkably hard for big organizations to sustain any of them over time.
…
That’s the problem with any new technology: You can proceed cautiously and probably do just fine. Big companies hate risk, which is why they operate as well-oiled machines churning out reliable products at an affordable cost. That’s also why many of them outsource their innovation by acquiring startups — and even that approach often leads to timid improvements. All successful organizations, especially at size, prefer to minimize risk and daring. But as Brené Brown points out, “You can choose courage, or you can choose comfort, but you cannot choose both.”
…
The startup mindset is not just about courage and flexibility; it also involves a ferocious commitment to big achievement, a kind of hero’s journey to address a great challenge. Instead of predictability churning out good products at scale — though that’s a perfectly worthwhile goal — startups want to create something extraordinary. So they put a premium on looking around, flexibly partnering with others. They dispense with existing structures and biases, no matter how old and respected, in order to get done what needs to be done.
…
Companies can’t adopt these drivers overnight, but they can start moving toward a point of serious commitment to new possibilities. Most of those drivers also work at the level of individuals looking for purpose and achievement in their own careers. They can embrace boldness, adopt a startup mentality, and other imperatives. Like companies, employees can invest aggressively in AI by acquiring the requisite skills and experience — thereby not just protecting their careers, but adding value at a higher level.Much of corporate life has quite properly been about churning out reliable products at low cost. What we need now, to prevent mass unemployment, is for many firms to break out of this discipline and speed up the AI future. The great danger is that most companies will play it safe, make the easy investments, and do fine in the short term.
We’ve already started to see companies positioning in one of the two camps described in this article. You know which ones are in which camp if you have read Synthetic Work long enough.
We’ll have to wait quite some time to see the consequences of their decisions.
The third thing worth your attention this week is a new research paper on the economic impact of AI-powered software development solutions like Copilot.
The paper, titled Sea Change in Software Development: Economic and Productivity Analysis of the AI-Powered Developer Lifecycle is authored by the GitHub CEO, Thomas Dohmke, a professor at the Harvard Business School, Marco Iansiti, and the CEO of Keystone Strategy, Greg Richards.
The paper is not peer-reviewed yet, and you should expect some bias in favor of Copilot for obvious reasons. Nonetheless, the research sample is enormous and, for this alone, worth reading.
What’s interesting in this paper?
First:
GitHub Copilot has a sizable productivity impact on developers that grows over time. In the first three months, developers accept approximately 30% of code recommendations. As developers overcome any learning curves and become more comfortable with the tool, they use it for even greater impact and accept more code suggestions.
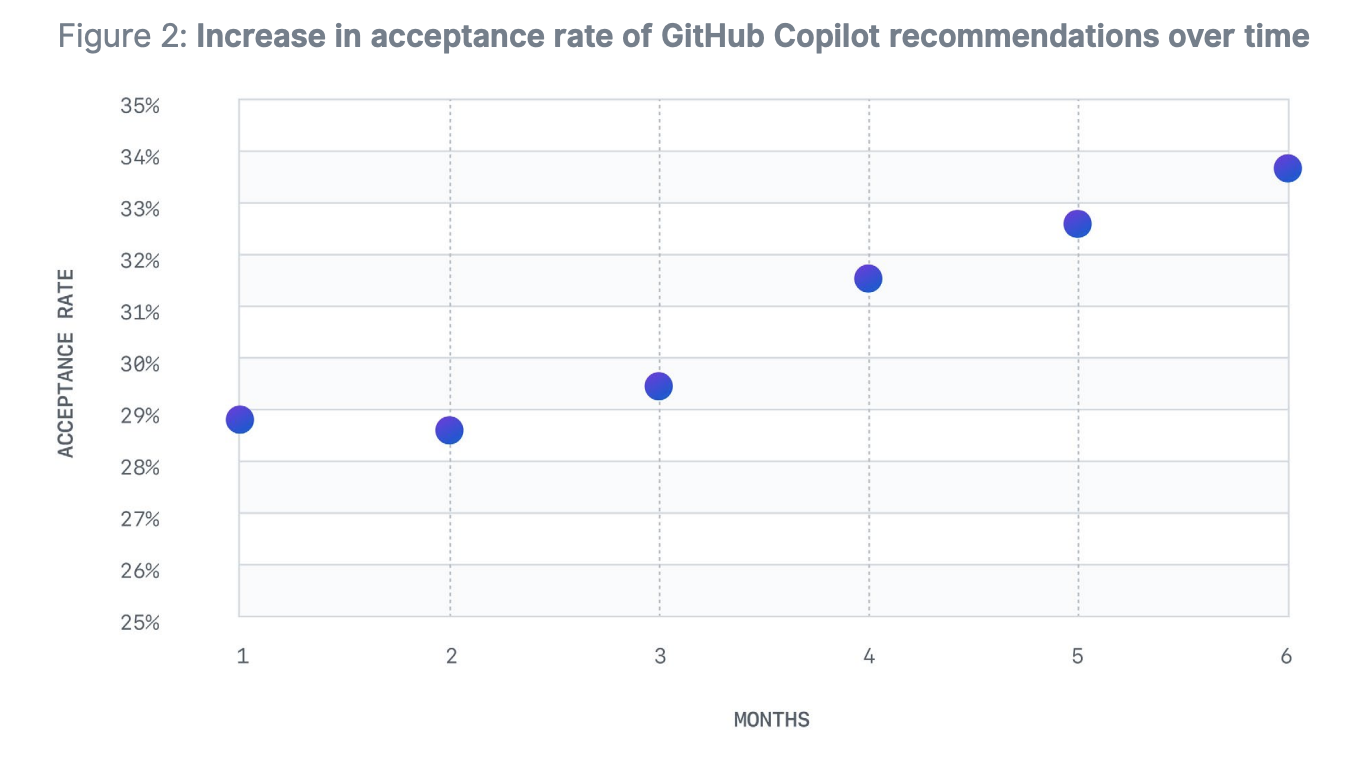
It’s pure coincidence that I dedicated this week’s entire Splendid Edition to how to turn Visual Studio Code into the ultimate writing tool for non-technical people. The central feature of that setup is Copilot and, while I use it to generate sentence recommendations rather than code recommendations, my subjective experience with it is in line with the 30% figure. Rigorous research is necessary in this area.
Second:
With a sample of nearly one million developers, the data demonstrates GitHub Copilot’s potential to substantially impact productivity for the developer community. As developers continue to become fluent in prompting and interacting with AI, particularly with new models that allow natural language to power the development lifecycle, we anticipate that approximately 80% of code will be written with AI.
The last time GitHub said something like this was February 2023. At that time, the company reported that Copilot was behind an average of 46% of a developers’ code across all programming languages.
Now we are talking about 80% of the output.
Even if this number is overly optimistic, two things come to mind:
- Let’s say that the idea of autocompleting plain English, as I described it in the Introduction of Issue #16 – Discover Your True Vocation With AI: The Dog Walker, takes off. It wouldn’t be unthinkable that it would follow the trajectory described here for software development.
- Let’s say that this scenario unfolds, and we end up with an AI generating 80% of anything we output in written form. Do you remember the point raised in the Introduction I mentioned?
How much power a company would have at that point to nudge and influence how we think and the shape of what we produce?
Third:
Globally, there is a growing demand for software and simply not enough developers. Currently there are an estimated 27 million professional software developers in the world. In Europe, the shortage in IT jobs is estimated at over 500,000, with Germany exceeding 100,000, and countries like Denmark, Norway, and Sweden expected to face growing demand. Latin America faces a similar shortage, with a deficit of IT workers in Brazil growing at an estimated 25,000 per year. According to an estimate by Korn Ferry, the shortage of tech talent could be 85.2 million in 2030 across various sectors.
Generative AI tools hold promise here, not only to skill more developers, but also to make each and every developer more productive.
…
Using 30% productivity enhancement, with a projected number of 45 million developers in 2030, generative AI could add an additional 15 million “effective developers” to worldwide capacity in that timeframe.
…
Consistent with our assumptions, a Korn Ferry report estimates that there will be a shortage of 85.2 million jobs across skilled workers, amounting to a loss of $8.4 trillion USD to global GDP by 2030.39 The report therefore suggests that each missing skilled worker could be responsible for nearly $100,000 USD in GDP loss by 2030. Assuming that the average developer’s impact is similar to or higher than the impact of a skilled worker (which also seems quite conservative), having 15 million additional developers could then translate to an increase of as much as $1.5 trillion USD.
In other words, the narrative is: AI can help us mitigate the shortage of software developers. And there is no question that this is true. More than that, if properly implemented, AI could help us write more secure software, suggesting quality code to junior developers that only veterans can write.
The scenario is tantalizing.
But the question in my mind is always if there’s a point of no return and where that point is: the numbers in this research assume that by 2030 we have not evolved today’s AI models to the point where they can write code on their own with a quality that can match a human developer.
If you heard of projects like AutoGPT, you know that we are far away from that, but we are going in that direction. The AI community has already started talking about the transition from large language models (LLMs) to large action models (LAMs).
And if we manage to improve at the same rate Midjourney has improved in 12 months, to make a silly, apple-to-oranges comparison, then we have no certainties about what AI models will be able to do in seven years.
If and when we’ll start to see serious self-writing capabilities, I hope that we’ll also see research from GitHub on what could happen if Copilot turns into an Autopilot, and what we can do to mitigate the risks in case Autopilot is not a good thing.
We can have both self-writing software, unlocking unlimited abundance, and a healthy society. We just need to plan for it.
As OpenAI, GitHub, and Microsoft have the potential to enable the former, I hope to see them take the lead in safeguarding the latter.
This is the material that will be greatly expanded in the Splendid Edition of the newsletter.
Picture this: you watched 19 years of Grey’s Anatomy in TV. You are not a doctor. In fact, you are an acrobat working for The Cirque du Soleil. Yet, 19 years are 19 years, and you think you have kind of understood a few basic things about medicine.
One day somebody offers you money to say what you know about medicine. You don’t know that, secretly, your answers will be used to train actual medical students to become doctors. You just think it’s a survey about Grey’s Anatomy and you need the extra money. So you say yes.
When the time to answer the questions come, you discover that you don’t know how to respond to plenty of questions. So you improvise. You do your best to guess the most likely answer based on 19 years of binge-watching.
Your answers are passed to the medical students, and some of them are objectively correct. So the students are learning something. But the other answers are wrong and the students are building their knowledge on a pile of guesses.
In time, these students get to participate in the same survey you just did. It’s expensive to be a medical student. Plus, they have the knowledge now. They can do this.
So they start answering the questions passing on the pile of guesses they have learned from you, the acrobat at the Cirque du Soleil. Unbeknownst to them, their answers, combined with the answers of other acrobats like you, are passed to the next generation of medical students.
So, now, we have a body of knowledge composed of some correct answers (thanks, Grey’s Anatomy), your wrong guesses, and a lot of new wrong guesses from others.
Imagine this cycle repeating itself for a while.
Why am I wasting your time with this story? Because there’s money to be made. Read on.
In the last couple of weeks, you might have read the story of people working for the Amazon Mechanical Turk service using AI to do as little as possible.
If you don’t, Devin Coldewey, reporting for TechCrunch, will update you:
Amazon’s Mechanical Turk let users divide simple tasks into any number of small subtasks that take only a few seconds to do, and which pay pennies — but dedicated piecemeal workers would perform thousands and thereby earn a modest but reliable wage. It was, as Jeff Bezos memorably put it back then, “artificial artificial intelligence.”
These were usually tasks that were then difficult to automate — like a CAPTCHA, or identifying the sentiment of a sentence, or a simple “draw a circle around the cat in this image,” things that people could do quickly and reliably. It was used liberally by people labeling relatively complex data and researchers aiming to get human evaluations or decisions at scale.
…
a study from researchers at EPFL in Switzerland shows that Mechanical Turk workers are automating their work using large language models like ChatGPT.
If have never seen a Mechanical Turk task, here’s an example:

The authors of the paper (not yet peer-reviewed), Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks, warn in the abstract:
We reran an abstract summarization task from the literature on Amazon Mechanical Turk and, through a combination of keystroke detection and synthetic text classification, estimate that 33-46% of crowd workers used LLMs when completing the task. Although generalization to other, less LLM-friendly tasks is unclear, our results call for platforms, researchers, and crowd workers to find new ways to ensure that human data remain human, perhaps using the methodology proposed here as a stepping stone.
The irony of all of this is that the work of the crowd workers is used to train AI models.
It’s not that AI models cannot train other AI models. This happens all the time: Google has supposedly used the answers from ChatGPT to train Bard, and some independent AI teams with infinitely less resources than google have done the same to train smaller open access models based on a model trained by Meta called LLaMA.
There have been infinite conversations about the merits and risks of using synthetic data (i.e., data generated by AI models) in every field and use case where there’s a shortage of data that cannot be addressed in otherwise financially sustainable or scalable ways.
A fascinating new research published just last month, and titled The Curse of Recursion: Training on Generated Data Makes Models Forget suggests that using synthetic data to train AI models leads to “model collapse”, the dramatic way of the AI community to say that the model start generating awful results:
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
Remember that you are an acrobat at the Cirque du Soleil that binge-watches Grey’s Anatomy? And that other acrobats like you participate the survey to answer medical questions?
There. After a few cycles of that, the amount of crap that ends up in the medical students’ hands is so big that there are very few right answers left to learn from.
The medical students are AI models, and this is model collapse.
Here’s how it looks:

The bottom line is this: if we all work really, really hard to cut the corners and collapse all the models, we will end up with people paying us a lot more money to answer surveys about Grey’s Anatomy on Amazon Mechanical Turk.
I can’t see what could possibly go wrong with this wonderful plan.
The protagonist of this week is a startup called Outset.ai, which has the following pitch:
Getting answers to tough, qualitative questions from your users is extremely costly (in time and money). Outset provides an AI-interviewer that conducts and synthesizes research interviews autonomously. Researchers get large-scale, in-depth data (almost) instantly.
It’s not quite as bad as Impossible Labs Limited, creators of Synthetic Users, a service that simulates focus groups with AI. We discussed about them in Issue #9 – If You Have Experience With Technologies Like AGI, You Are Encouraged To Apply.
But it has potential.
As a former industry analyst, I can confirm that it’s incredibly hard, time-consuming, and expensive to get qualitative data from users via research interviews. And summarizing what you have collected is a gruesome job that I wish nobody ever had to do.
In this, the startup is right.
However, what this company is not telling you is that people seldom say what they really mean. Not because they are intentionally lying, but because they struggle to articulate their thoughts and feelings unless relentlessly probed and left free to roam in their exposition.
Unless you poke at them with skillfully-crafted follow-up questions, you often get useless or misleading answers.
Connected to this, and crucially, a master interviewer is capable of working outside the scope of the question being asked, and realizing that the interviewee is describing a problem that is in a completely different place from where the researcher expected to find it.
That’s where the real insights come from.
Unless the AI is not capable of that, and it’s not even close today, what you end up with is a ghost of an interview where all the nuances and unexpected insights are lost. In other words, a mass of interviews reinforcing the pre-existing biases of the people that have shaped the questions in the first place.
You think nobody would shoot themselves in the foot like that, but I’ve seen plenty of MBAs ordering multiple-choices answers in order of what they thought would be the most likely answer.
I’ve also seen industry veterans crafting questions in such a way that they could have been the inventors of the expression “leading the witness”.
Of course, none of this matters, because the overwhelming majority of people funding a market or product research have no interest whatsoever in finding the truth. They just need data to prove that their theory is right to gain political power, budget, resources, recognition, a bonus, nuclear missiles, and so on.
It’s only months or years later, when the product or the campaign fails, that somebody, timidly, dares to say “But the market research said…”
Been there, done that.
Bonus: what do you think it’s going to happen if the startup fails to get enough humans to answer the questions?
I’ll let you guess: it starts with “synthetic” and ends with “ata”.
Remember: you are a Cirque du Soleil acrobat and there’s money to be made here.
In the introduction of Issue #16 – Discover Your True Vocation With AI: The Dog Walker, I talked how I ended up using an application meant for software developers, Visual Studio Code, as my main writing tool.
If you haven’t read it, please go ahead and do so now. It’s critical to understand the context of today’s newsletter.
If you have read it, you know that I discovered, by accident, how CoPilot, the GitHub extension for VS Code based on GPT-4, is the ultimate help for writers, not just software developers.
What I didn’t tell you in that introduction is that, together with CoPilot, I use several additional extensions (some discovered just days ago) that have transformed my writing workflow to the point that today I can’t imagine writing anything of substance without VS Code.
So, today, we talk about how VS Code can become the ultimate life-changing personal writing tool, beating hands down any other tool you ever tried, from Ulysses to Scrivener, from Word to Google Docs.
Notice that I said, “personal”. The one shortcoming of using VS code to write is that it doesn’t have a collaboration feature, but so do many other writing apps on the market today. What I got with VS Code plus the extensions I’ll talk about below is so valuable that I’m happy to copy my draft from VS Code to Google Docs for the final editing and collaboration phase rather than write the whole thing there.
It’s that good.
We need to talk about three things: the extensions, the native tools, and the configuration of the environment. One complements the others and together they power my workflow.