
- Intro
- Synthetic Work’s AI Adoption Tracker now documents 100 early adopters and use cases around the world
- What’s AI Doing for Companies Like Mine?
- Learn what US Space Force, Accenture, and Spotify are doing with AI.
- A Chart to Look Smart
- The Federal Reserve Bank of St. Louis is exploring the use of generative AI to forecast inflation. The results are surprising.
- What Can AI Do for Me?
- My new AP Workflow 5.0 is ready to generate images at scale for industrial applications
- The Tools of the Trade
- Is the new Descript voice cloning service ready for prime time?
100! A hundred early adopters across the world are now listed in Synthetic Work’s AI Adoption Tracker.
Of course, there are many more early adopters than a hundred all around the world. But these are confirmed, verifiable, and researchable use cases. Not the handwaving of overexcited (and not necessarily honest) technology vendors.
A tremendous research tool I wish I had when I was an analyst for Gartner a life ago.
![]()
I expect to give many presentations to customers about these 100 adopters, as more and more organizations look for guidance and inspiration to adopt artificial intelligence. I’ll start in Italy, this December, where I’m invited by a company in the Professional Services industry to kick off their internal AI hackathon.
To the next 100.
Alessandro
What we talk about here is not about what it could be, but about what is happening today.
Every organization adopting AI that is mentioned in this section is recorded in the AI Adoption Tracker.
In the Defence industry, the US Space Force has been using a special large language model to generate text and query information from a wide range of data sources.
Katrina Manson, reporting for Bloomberg:
The Sept. 29 memorandum, addressed to the Guardian Workforce, the term for Space Force members, pauses the use of any government data on web-based generative AI tools, which can create text, images or other media from simple prompts. The memo says they “are not authorized” for use on government systems unless specifically approved.
…
Generative AI “will undoubtedly revolutionize our workforce and enhance Guardian’s ability to operate at speed,” Lisa Costa, Space Force’s chief technology and innovation officer, said in the memo. But Costa also cited concerns over cybersecurity, data handling and procurement requirements, saying that the adoption of AI and LLMs needs to be “responsible.”
…
The Space Force’s decision has already impacted at least 500 individuals who were using a generative AI platform called Ask Sage, according to Nicolas Chaillan, the company’s founder. Ask Sage aims to provide a secure generative AI platform that works with several LLM models including those from Microsoft Corp. and Alphabet Inc.’s Google, according to Chaillan.
…
Besides customers throughout the defense industrial base, Chaillan said more than 10,000 customers in the rest of the Defense Department, including 6,500 in the Air Force, are still using his company’s software. Some Defense Department users even pay the $30-a-month fee out of their own pocket, he said, adding it was helping them ease the burden of writing reports.“Clearly, this is going to put us years behind China,” he wrote in a September email complaining to Costa and several senior defense officials, in which he argued his service had already been “whitelisted” and approved for use by the Air Force, according to correspondence reviewed by Bloomberg.
…
Tim Gorman, a Pentagon spokesperson, told Bloomberg in July that defense services and agencies are allowed to temporarily authorize Ask Sage to process, store and transmit unclassified information that is releasable to the public. Ask Sage is also seeking authorization from the Defense Department to work with controlled information that cannot be released to the public.

All of this while the Pentagon urges AI Companies to be more transparent about their technology.
Again, Katrina Manson, reporting for Bloomberg:
Craig Martell, the Pentagon’s chief digital and artificial intelligence officer, wants companies to share insights into how their AI software is built — without forfeiting their intellectual property — so that the department can “feel comfortable and safe” adopting it.
…
“They’re saying: ‘Here it is. We’re not telling you how we built it. We’re not telling you what it’s good or bad at. We’re not telling you whether it’s biased or not,’” he said.He described such models as the equivalent of “found alien technology” for the Defense Department. He’s also concerned that only a few groups of people have enough money to build LLMs.
…
Martell is inviting industry and academics to Washington in February to address the concerns. The Pentagon’s symposium on defense data and AI aims to figure out what jobs LLMs may be suitable to handle, he said.Martell’s team, which is already running a task force to assess LLMs, has already found 200 potential uses for them within the Defense Department, he said.
“We don’t want to stop large language models,” he said. “We just want to understand the use, the benefits, the dangers and how to mitigate against them.”
…
Martell said his office is playing a consulting role within the Defense Department, helping different groups figure out the right way to measure the success or failure of their systems. The agency has more than 800 AI projects underway, some of them involving weapons systems.
Just 800 projects.
Expect Microsoft (with OpenAI), Google, and Amazon (with Anthropic, Cohere, and StabilityAI) to compete heavily on a version of their AI models that can handle classified information. Just like they do with the government version of their cloud services.
In the Professional Services industry, Accenture is testing the use of large language models as “advisors” for call center agents.
Andreo Calonzo, reporting for Bloomberg:
Like the rest of the world, the Philippines is bracing for disruption from AI, as bots take on more call center jobs. Adapting to the technology is crucial for the Philippines, whose outsourcing sector accounts for around 8% of economic output and is a top source of dollars.
…
Accenture Plc.’s Philippine unit is studying the use of AI-powered “co-pilots” as “advisors” for call center agents, and to help their coders understand and create codes.
…
Industry head Madrid said the prospects for the outsourcing sector remain bright despite the challenges posed by AI. This year, the industry expects to achieve 23% of the 1.1 million jobs and a fifth of the US$29.5 billion additional revenue it’s targeting by 2028.“Artificial intelligence plus our emotional intelligence will be a very potent combination,” Madrid said.
Needless to say, the last statement assumes that AI agents will never be able to mimic human empathy, but there’s a growing body of evidence that suggests otherwise.
Business leaders around the world only know a fraction of the things that generative AI seems capable of doing. Their forecasts must start to take into account more of the research that gets published every day.
In the Broadcasting & Media industry, Spotify is now using AI to generate the transcription of millions of podcasts and clone the voice of the podcasters in other languages.
Mia Sato, reporting for The Verge:
The text transcripts will also be time-synced so listeners can visually follow along as a podcast episode progresses. Transcripts are available by scrolling down below the podcast player and tapping into a “read along” section. A transcription of a show makes the podcast more accessible to users and allows listeners to skip around and skim an episode without listening through.
Spotify says “millions” of podcast episodes will get the tool, and in the future, creators could add media to transcripts — a useful feature if a creator is describing an image on the show, for example.
Amrita Khalid, reporting for The Verge:
The company has partnered with a handful of podcasters to translate their English-language episodes into Spanish with its new tool, and it has plans to roll out French and German translations in the coming weeks. The initial batch of episodes will come from some big names, including Dax Shepard, Monica Padman, Lex Fridman, Bill Simmons, and Steven Bartlett. Spotify plans to expand the group to include The Rewatchables from The Ringer and its upcoming show from Trevor Noah.
…
The backbone of the translation feature is OpenAI’s voice transcription tool Whisper, which can both transcribe English speech and translate other languages into English. But Spotify’s tool goes beyond speech-to-text translation — the feature will translate a podcast into a different language and reproduce it in a synthesized version of the podcasters’ own voice.
…
OpenAI is likely behind the voice replication part of this new feature, too. The AI company is making a few announcements this morning, including the launch of a tool that can create “human-like audio from just text and a few seconds of sample speech.” OpenAI says it’s intentionally limiting how widely this tool will be available due to concerns around safety and privacy.
Why is this of particular importance?
Because, it’s the nth signal that, going forward, people will grow accustomed to having access to the transcription of everything and the ability to listen to video or audio content in any language they want.
This expectation will not remain confined within the boundaries of the Broadcasting & Media industry.
If your company produces video or audio content of any sort, you should start thinking about AI-powered accessibility in a very serious way.
You won’t believe that people would fall for it, but they do. Boy, they do.
So this is a section dedicated to making me popular.
The Federal Reserve Bank of St. Louis is exploring the use of generative AI to forecast inflation. The results are surprising.
We explore the ability of Large Language Models (LLMs) to produce conditional inflation forecasts during the 2019-2023 period. We use a leading LLM (Google AI’s PaLM) to produce distributions of conditional forecasts at different horizons and compare these forecasts to those of a leading source, the Survey of Professional Forecasters (SPF). We find that LLM forecasts generate lower mean-squared errors overall in most years, and at almost all horizons. LLM forecasts exhibit slower reversion to the 2% inflation anchor. We argue that this method of generating forecasts is inexpensive and can be applied to other time series.
Inexplicably, the researchers decided to use the large language model that performs the worst on the market: PaLM, which powers Bard.
How did it perform?
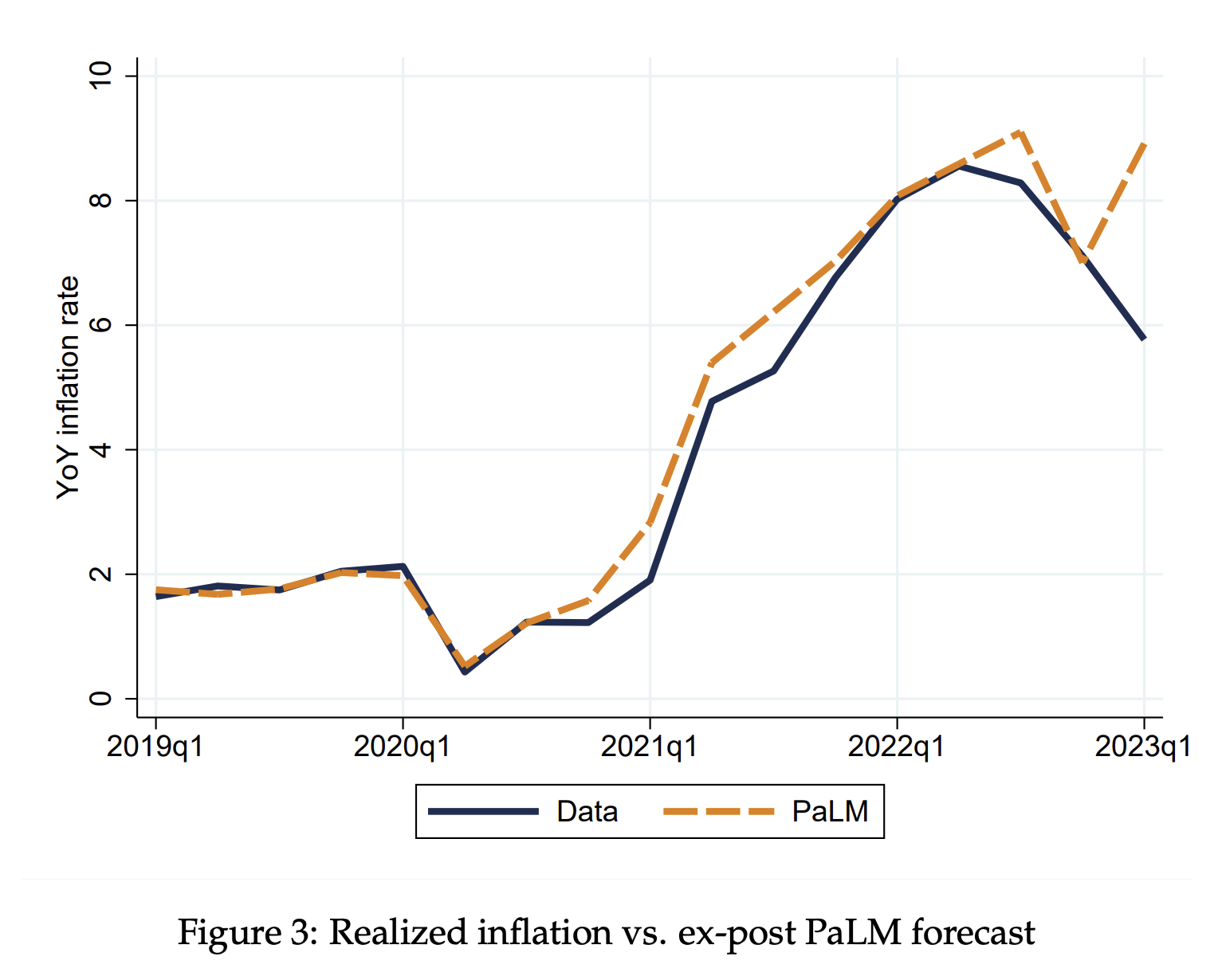
The paper explains:
even though the model has been trained with data posterior to the date of the forecast, the model appears to ignore the realized inflation dynamics and instead provides an inflation forecast that differs systematically from it.
We interpret these findings as further evidence that the conditional inflation forecasts obtained through PaLM are indeed likely to capture the inflation that the model would have forecasted in the past when restricted to the respective information sets.
…
PaLM underperforms relative to the SPF in 2019 and 2023, but significantly overperforms in 2020-22. The performance is particularly better in 2021 and 2022.
…
Standard measures of forecast performance suggest that PaLM, the LLM we focus on, is able to generate conditional forecasts that are at least as good if not better than one of the most trusted and respected sources of inflation forecasts, the SPF. We believe that this is relevant for agents, practitioners and policymakers alike, as technological improvements in hardware and software are likely to significantly reduce the cost of developing and training these models. LLMs may then become an accessible means to generating forecasts, especially when compared to potentially costlier surveys of experts and households.In this paper, we have focused on year-over-year growth rates of the Consumer Price Index, a variable for which there exists a multitude of forecasts. This choice provides us with plenty of different alternatives against which we can benchmark the LLM forecasts. We think, however, that LLMs may become particularly useful in terms of forecasting variables for which we do not
conduct surveys, and/or for which such surveys would be expensive and complicated to design and implement. These include, for instance, disaggregated time series variables such as labor force indicators for specific demographic groups or household disposable income for specific geographical regions, among others.
Assuming there are no errors in the paper, the burning question is: what if large language models could be used by a public company to generate more accurate forecasts before earnings calls?
If I were in contact with the CFO office, I’d urge them to start looking into this.
When people think about a type of generative AI called text2image (T2I), they usually think about generating a handful of images to share on social media for fun. To do that, you can use Midjourney (if you are comfortable using Discord as user interface) or the new Dall-E 3. Very fast services that can generate pleasant, high-quality images in a matter of seconds.
When business people think about T2I, they think about generating stock images that can be used in company presentations, marketing materials, video demos, etc. at a fraction of the cost we pay today for stock image photo subscription services.
In reality, T2I can do a lot more for large organizations, thanks to the power of automation.
For example, in Issue #15 – I’d like to buy 4K AI experts, thank you, we saw how the company Carvana used generative AI to produce 1.3 million personalized video ads for its customers to celebrate 10 years in business.
They built a cloud-based system capable of rendering up to 300,000 videos per hour, each personalized for an individual customer with the model of car they bought, the location, and more.
How do you think they did that?
With automation.
Another example: in Issue #11 – Personalized Ads and Personalized Tutors, we saw how the giant ad agency WPP use generative AI to personalize the video of the Bollywood superstar Shah Rukh Khan promoting a famous brand of chocolate.
They built hundreds of thousands of variants of the same video, where the actor pronounced the name of a local business across India to celebrate Diwali.
How do you think they did that?
With automation.
So, today, let’s talk a little bit more about that. Whether you are an ad agency, a production studio, or a large enterprise organization, the right tool and knowledge will open a world of possibilities for you.
The right tool, in this particular case, is called ComfyUI.
But don’t worry, we are not going to talk about the technical details of how to build a system like the ones used by Carvana and WPP with ComfyUI. We’ll not be technical at all, and the whole point is only to give you a sense of what’s possible today.
I talked a little about ComfyUI in the Intro of Issue #27 – Blind Trust, but back then the excuse was to think together about what would happen once generative AI models become capable of generating precise diagrams and charts, and automation allows people to spread them at scale.
Today, instead, I want to show you how the automation of ComfyUI and the magic of Stable Diffusion could generate images at scale for your organization, just like Carvana and WPP did for their customers.
To explore the possibilities, in the last few months, I worked untold hours on further developing the automation workflow you saw in Issues 26 and 27, working with many members of the AI community to develop its many capabilities.
I called AP Workflow in the least creative moment of my life.
(Clearly “AP” comes from the initials of my name, but as I write this, GPT-4 suggests that the letters could mean “Automation and Personalization” – I might take credit for that in a near future)
As we speak, I’m about to release AP Workflow 5.0, which will introduce several critical features that matter for the conversation we are having today.
The first one is the capability to ingest a large number of images and process them one after the other:
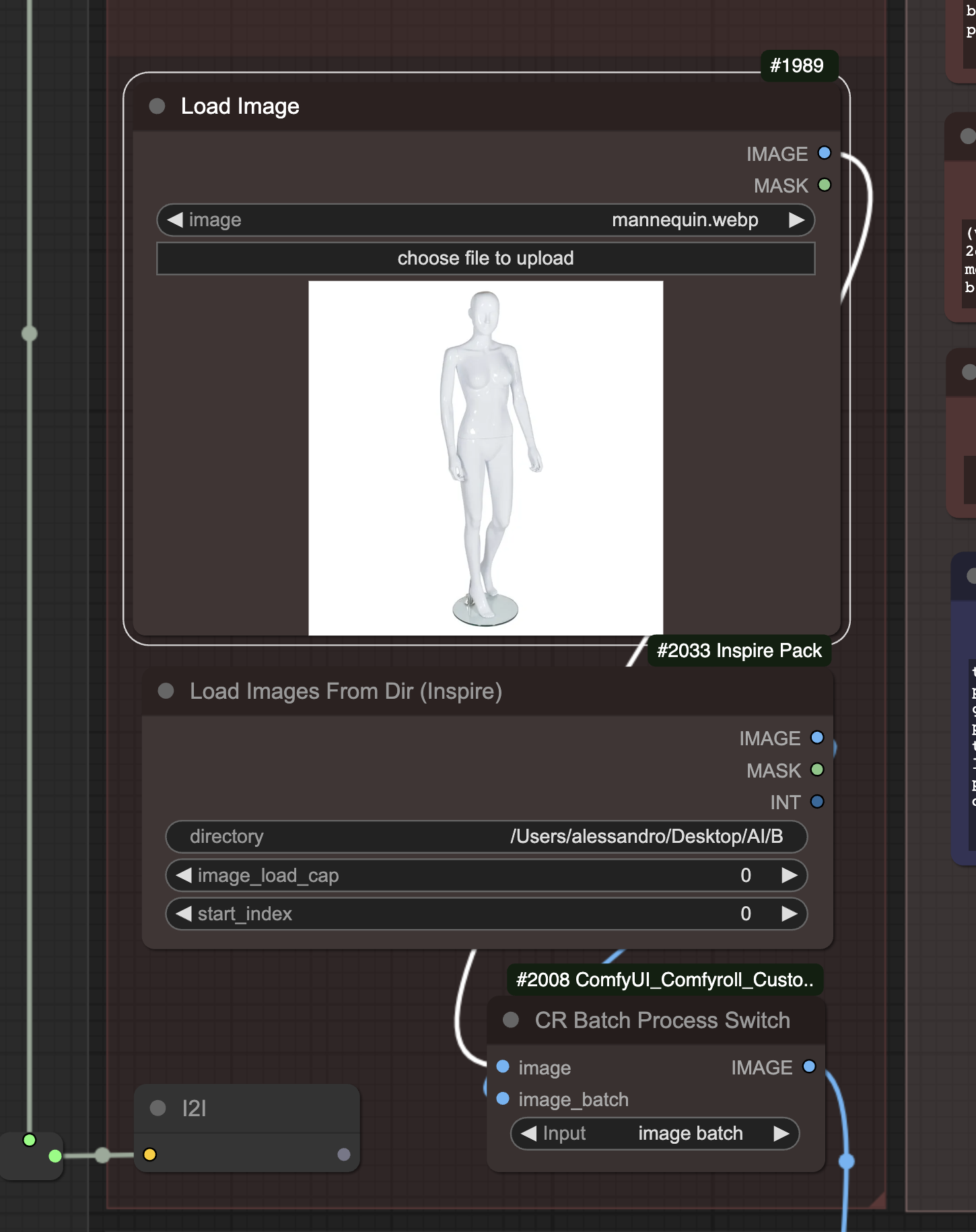
Imagine that, instead of the image of a mannequin, you could upload the pictures of hundreds of models, of different genders, ethnicities, and physical traits.
One by one, these images could be passed to other section of the workflow that, thanks to machine learning, identifies different parts of their bodies and correctly display clothes or accessories on them.
For example, my AP Workflow 5.0 correctly identifies faces, hands, feet, eyes, noses, and mouths, to automatically improve their anatomy when Stable Diffusion doesn’t do a great job with the initial generation.
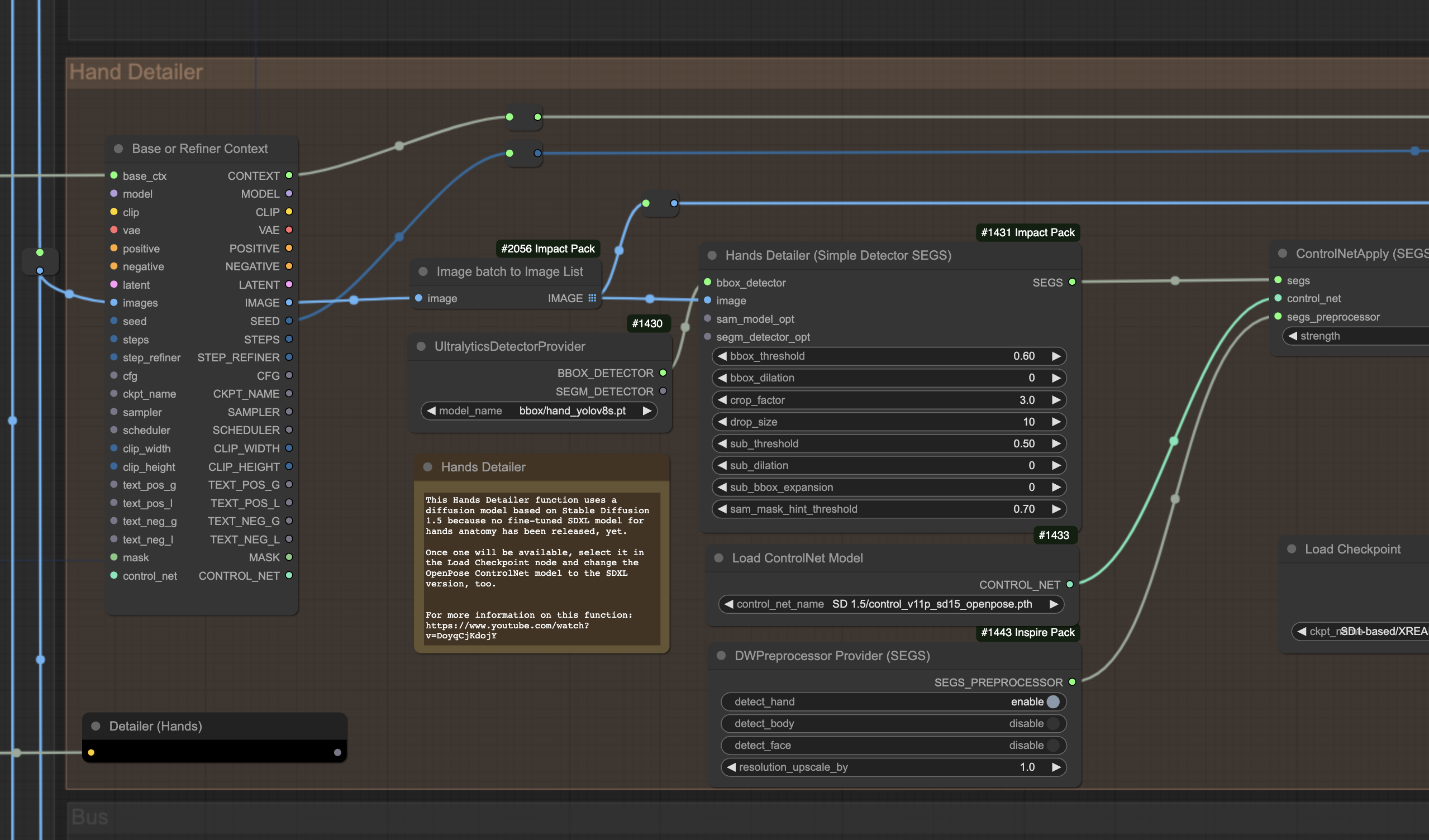
I don’t have to do anything manually. The automation workflow identifies the hands and generates an anatomical skeleton of the bones, no matter their position. It then uses a fine-tuned version of Stable Diffusion to re-generate the hands with the correct anatomy.
I could replace the model that re-generates the hands with a model that places a handbag in the hand of a model, or a watch on his/her wrist, or a skirt on his/her legs, or a pair of shoes on his/her feet.
Doing the same with human artists would require thousands of hours of work, and it would cost a prohibitive amount of money for small companies.
The second feature of AP Workflow 5.0 that is relevant for today’s conversation is a new prompt enricher: a section of the workflow that takes the prompt written by your user and expands it with additional information thanks to the help of OpenAI models.
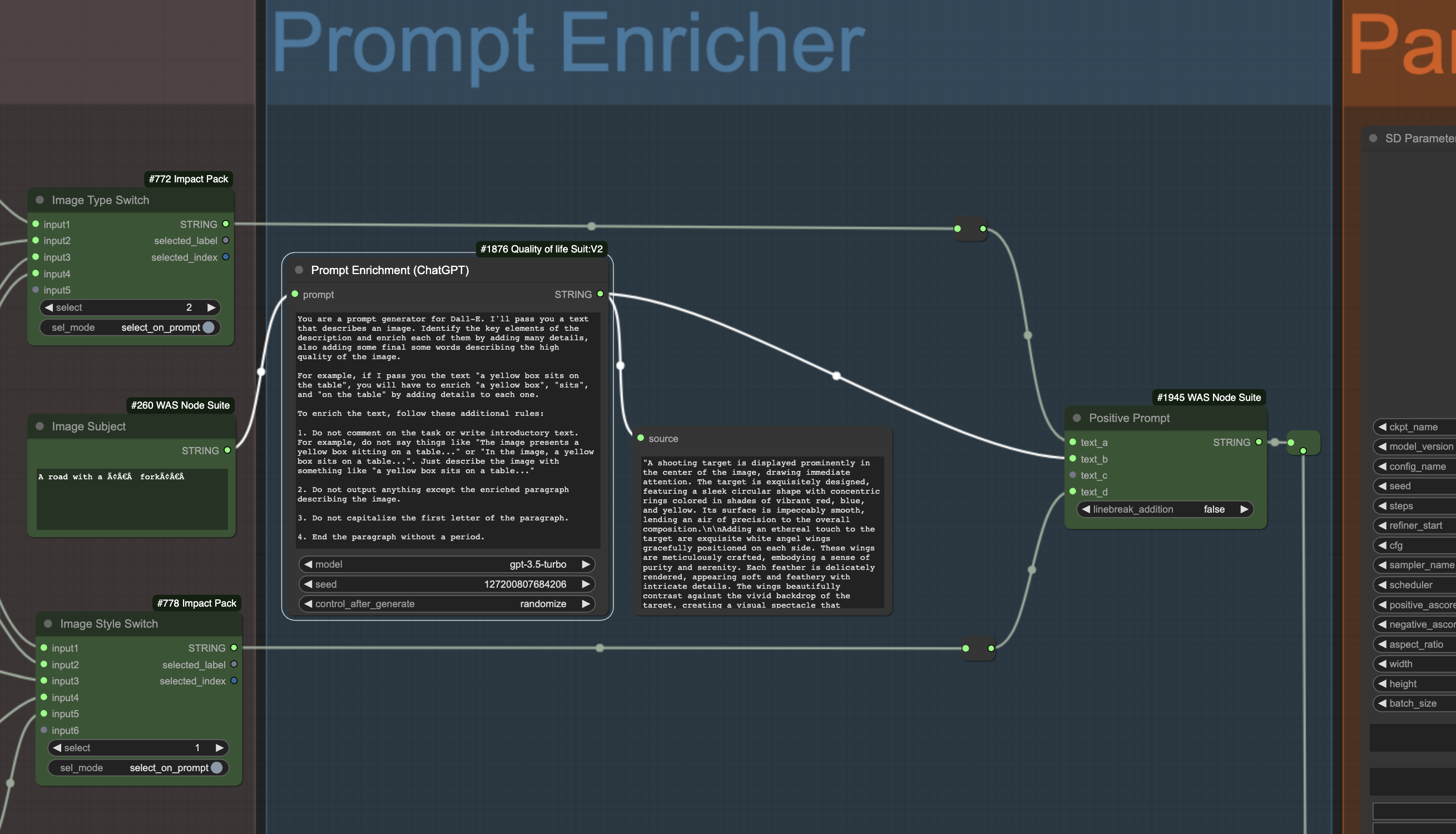
While the screenshot shows a standard approach to prompt enrichment, you can imagine a scenario where your instructions for GPT-4 include specific corporate guidance.
For example, if you are Coca-Cola, you might instruct GPT-4 to enrich the prompt of the user to always place a Coca-Cola bottle in the hand of the model, or to always place a Coca-Cola shop somewhere in the image.
In this way, your users don’t have to remember to do that, and you can be sure that your brand is always represented, no matter what’s the image generated by the AI model.
This is possibly what the Midjourney team did when, for a period of time, the images users generated always included the Coca-Cola logo somewhere in the image. We saw that in Issue #6 – Putting Lipstick on a Pig (at a Wedding).
The third new feature of AP Workflow 5.0 that is relevant for today’s conversation is the infamous face swap technology, which allows you to replace the face of a person with another in certain types of images.
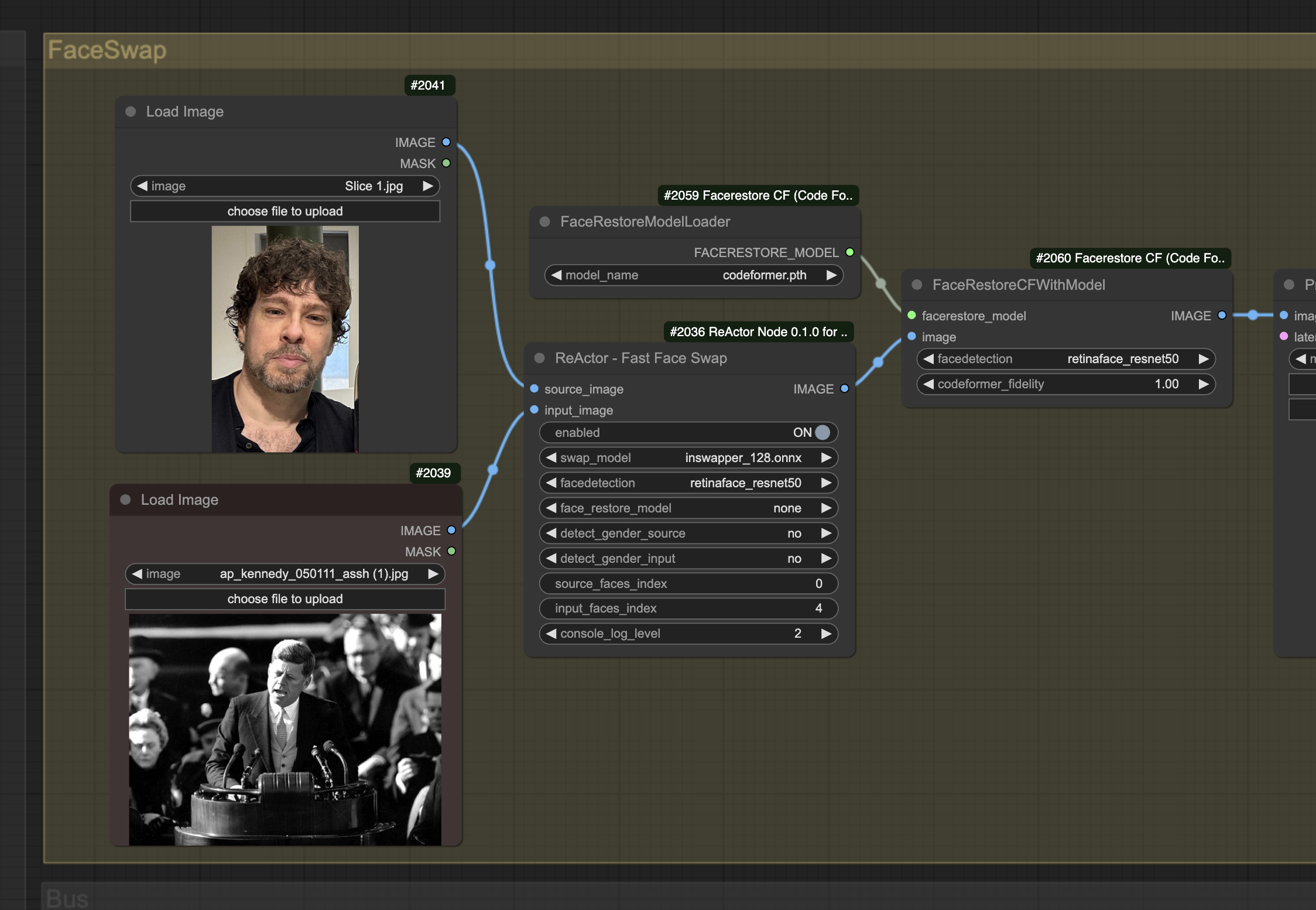
The power of this technology is enormous and the implications that come from its misuse hard to quantify. As I wrote on various social media networks:


However, there are also industrial applications for this technology.
Of course, swapping the face of a stunt with the face of an actor in dangerous or complex scenes is the first example that comes to mind, but we are not all Hollywood studios.
Imagine, instead, the capability to personalize the face of the model in the image with the face of your customer, to let them visualize themselves wearing your product.
Or the capability to place the face of your very busy CEO in every image generated by the company for your customers, to make them feel more connected to your brand.
Or the capability to place a very specific historical figure in a variety of situations, for education purposes.
Face swapping can be also used in reverse, to remove the face of a person from the image, to guarantee their privacy. For example, in training material.
All these things can be done at scale, with automation, and at a fraction of the cost of human labor available today.
And there are many services and popular apps that already do some of these things today, albeit for more trivial reasons. Behind the scenes, some of them, use ComfyUI and an automation workflow like the one I created.
AP Workflow 5.0 will be available for free in the coming days at this address: https://perilli.com/ai/comfyui
This week, Descript, a video and audio editing tool we talked a lot in the past, is launching a new version of its Overdub feature.
As a reminder, Overdub is the name they give to the capability to clone your voice and use that synthetic version to create a new spoken dialogue, or edit an existing one, in the same frictionless way you’d edit a document in a word processor.
This AI application is transformative if you or your team need to create distributable marketing presentations, product demos, internet or TV commercials, podcast shows, and so on.
The cost of producing these assets drops dramatically as you don’t need to recall a voice actor or a speaker if you want to change something in the script last minute, or if an error was made. Depending on the quality you aim for, you might not need the voice actor or speaker at all.
Of course, this also has implications on the profession of voice actors and speakers, something we discuss extensively in the Free Edition of Synthetic Work.
What’s notable in this new version of Overdub and why it matters?
- Instant cloning: Speech cloning technology has made enormous progress in the last year and we moved from the need for 30 minutes of human speech to clone a voice to just 3 seconds. To clone your voice (or any voice you have permission to clone), Descript wants you to read an authorization statement that will take you less than 30 seconds to be spoken. After that, your synthetic voice will be generated almost instantaneously.
- Higer voice quality: The quality of the new synthetic voices generated by Overdub 2 is significantly better than the previous generation. Every company is taking advantage of more realistic text-to-speech (TTS) engines released by the AI community in the last few months, and so Descript joins Play HT, ElevenLabs, and many others in upgrading voice quality.
On the last point, voice quality is not just about how natural the voice sounds, but also how good it pronounces words or letters in edge cases. For example when there are initials, or when you use a single foreign word in an otherwise English sentence.
If these edge cases are not handled well, the production time (and cost) skyrockets back up, because you end up spending more time addressing all the exceptions than you would have spent by just recording a human actor.
So, now, Descript claims that the quality of their new voices is so good that you can now confidently use them to record an entire script without any human voice actor involved.
I checked if this and the other claims are true.
First, I cloned my voice (probably giving Descript the right to reuse me in ways that I’ll deeply regret 50 years from now, but I would do anything for Synthetic Work members.
Nothing to report about the process: it’s as quick as promised. Not having to commit 30 minutes of my time to read in a very silent room removes a lot of the friction in the process.
But did they clone my voice well? Let’s hear it:
(the gibberish you hear across the video is because I didn’t upgrade my subscription for this demo)
I think you’ll agree with me that the quality of the voice is quite good, but not yet a perfect clone of my voice. It’s more like a blend of my voice and one of Descript stock synthetic voices. Which is probably good enough for many projects.
More importantly, despite my every effort to recite the authorization statement with theatrical emphasis, to allow the AI model to capture a wide range of emotions, pitch, and tone, my cloned voice is quite flat.
It’s very usable, but quite boring compared to the performance of a voice actor.
What’s the problem? If the cloned voice is not exceptional, why can’t we just use a Descript stock voice?
Well, there are two problems with that:
- The first problem is that the entire planet is using their stock voices. So your chances to differentiate your video are dramatically reduced. Other companies, like Play HT, allow you to create variants of each stock voice, which helps, but it doesn’t address the next problem.
- The second problem is that people react to familiar voices in a remarkable way. Familiar voices build trust, and trust moves the world. We talk extensively about this in the Free Edition of Synthetic Work. So, when given the choice between using a synthetic stock voice, or the cloned voice of one of your executives, or a product manager beloved for his/her product demos, you should always pick the latter.
So, the question becomes: can a more specialized player like ElevenLabs do any better?
To find out I cloned my voice with their service, too.
Differently from Descript, ElevenLabs requires you to upload one to twentyfive audio or video samples for a total of 5 minutes of spoken dialogue. Lots more friction.
Here’s the same video with my ElevenLabs synthetic voice:
I hope you’ll agree with me that Eleven Labs has a massive advantage here. It’s clear that, like Descript, ElevenLabs instant cloning service has merged my voice with one of their stock voices. Yet, the resulting cloned voice is much closer to mine, and it’s more expressive and engaging.
I wish I had that kind of pronunciation so, at least in my case, it’s also very flattering.
However, despite ElevenLabs beats Descript hands down at cloning voices, the Descript experience is superior in every way, as their word processor approach to voice editing is much more intuitive and powerful than more traditional interfaces used by ElevenLabs, Play HT, and Coqui.
So, here’s some guidance on how to pick the best synthetic voice service on the market today:
- Play HT has the best quality voices you can find on the market. However, their engine still struggles with acronyms, abbreviations, and occasional foreign words in English sentences. The interface is frustrating, and it’s not designed for large-scale editing projects.
- ElevenLabs has the second-best quality voices on the market. Their engine struggles less than the Play HT one with acronyms and abbreviations, but it still has significant issues with the occasional foreign words in English sentences. Like for PlayHT, ElevenLabs interface is not designed for large-scale editing projects.
- Coqui Studio has the third-best voices on the marker. Their interface is the most powerful on the market in terms of how much you can customize the pronunciation of each word, but it’s exceptionally frustrating and clearly optimized to generate very short sentences (like recurring expression in video games). Unsuitable even for medium-length editing work. That said, their commercial offering is based on an open source project, so if you are looking for the ultimate flexibility in terms of what a synthetic voice can do, that is the way to go.
- Descript has the fourth-best quality voices on the market. However, their interface makes editing so frictionless that you’ll likely want to start from their solution and move to the alternatives only if it’s truly disappointing.
To truly dominate the market, these solutions will have to converge to a point where users can enjoy the frictionless editing experience offered by Descript, the powerful voice editing of Coqui, the uncompromising sound quality of Play HT, and the generation speed of ElevenLabs.
There’s hope, as Eleven Labs has recently introduced a new section of their website called Projects, which is clearly inspired by Descript:
By the way, if you want to hear more about how their stock voices perform, you can check the podcast version of Synthetic Work Issue #28 Free Edition, which I published a few weeks ago: